71 items found
- The Ethics of Advanced AI Assistants: Explained & Reviewed
Recently, Google DeepMind had published a 200+ pages-long paper on the "Ethics of Advanced AI Assistants". The paper in most ways is extensively authored, well-cited and requires a condensed review, and feedback. Hence, we have decided that VLiGTA, Indic Pacific's research division, may develop an infographic report encompassing various aspects of this well-researched paper (if necessary). This insight by Visual Legal Analytica features my review of this paper by Google DeepMind. This paper is divided into 6 parts, and I have provided my review, and an extractable insight on the key points of law, policy and technology, which are addressed in this paper. Part I: Introduction to the Ethics of Advanced AI Assistants To summarise the introduction, there are 3 points which could be highlighted from this paper: The development of advanced AI assistants marks a technological paradigm shift, with potential profound impacts on society and individual lives. Advanced AI assistants are defined as agents with natural language interfaces that plan and execute actions across multiple domains in line with user expectations. The paper aims to systematically address the ethical and societal questions posed by advanced AI assistants. Now, the paper has attempted well to address 16 different questions on AI assistants, and the ethical & legal-policy ramifications associated with them. The 16 questions can be summarised in these points: How are AI assistants by definition unique among the classes of AI technologies? What could be the possible capabilities of AI assistants and if value systems exist, then what could be defined as a "good" AI assistant with all-context evidence? Are there any limits on these AI assistants? What should an AI assistant be aligned with? What could be the real safety issues around the realm of AI assistants and what does safety mean for this class of AI technologies? What new forms of persuasion might advanced AI assistants be capable of? How can appropriate control of these assistants be ensured to users? How can end users (and the vulnerable ones) be protected from AI manipulation and unwanted disclosure of personal information? Since AI assistants can do anthropomorphisation, is it morally problematic or not? Can we permit this anthropomorphisation conditionally? What could be the possible rules of engagement for human users and advanced AI assistants? What could be the possible rules of engagement among AI assistants then? What about the impact of introducing AI assistants to users on non-users? How would AI assistants impact information ecosystem and its economics, especially the public fora (or the digital public square of the internet as we know it)? What is the environmental impact of AI assistants? How can we be confident about the safety of AI Assistants and what evaluations might be needed at the agent, user and system levels? I must admit that these 16 questions are intriguing for the most part. Let's also look at the methodology applied by the authors in that context. The authors clearly admit that the facets of Responsible AI, like responsible development, deployment & use of AI assistants - are based on the possibility if humans have the capacity of ethical foresight to catch up with the technological progress. The issues of risk and impact come later. The authors also admit that there is ample uncertainty about the future developments and interaction effects (a subset of network effects) due to two factors - (1) the nature; and (2) the trajectory (of evolution) of the class of technology (AI Assistants) itself. The trajectory is exponential and uncertain. For all privacy and ethical issues, the authors have rightly pointed out that AI Assistant technologies will be subject to rapid development. The authors also admit that uncertainty arises from many factors, including the complementary & competitive dynamics around AI Assistants, end users, developers and governments (which can be related to aspects of AI hype as well). Thus, it is humble and reasonable to admit in this paper how a purely reactive approach to Responsible AI ("responsible decision-making") is inadequate. The authors have correctly argued in the methodology segment that the AI-related "future-facing ethics" could be best understood as a form of sociotechnical speculative ethics. Since the narrative of futuristic ethics is speculative for something non-exist, regulatory narratives can never be based on such narratives. If narratives have to be socio-technical, they have to make practical sense. I appreciate the fact that the authors would like to take a sociotechnical paper throughout this paper based on interaction dynamics and not hype & speculation. Part II: Advanced AI Assistants Here is a key summary of this part in the paper: AI assistants are moving from simple tools to complex systems capable of operating across multiple domains. These assistants can significantly personalize user interactions, enhancing utility but also raising concerns about influence and dependence. Conceptual Analysis vs Conceptual Engineering There is an interesting comparison on Conceptual Analysis vs Conceptual Engineering in an excerpt, which is highlighted as follows: In this paper, we opt for a conceptual engineering approach. This is because, first, there is no obvious reason to suppose that novel and undertheorised natural language terms like ‘AI assistant’ pick out stable concepts: language in this space may itself be evolving quickly. As such, there may be no unique concept to analyse, especially if people currently use the term loosely to describe a broad range of different technologies and applications. Second, having a practically useful definition that is sensitive to the context of ethical, social and political analysis has downstream advantages, including limiting the scope of the ethical discussion to a well-defined class of AI systems and bracketing potentially distracting concerns about whether the examples provided genuinely reflect the target phenomenon. Here's a footnote which helps a lot in explaining this tendency taken by the authors of the paper. Note that conceptually engineering a definition leaves room to build in explicitly normative criteria for AI assistants (e.g. that AI assistants enhance user well-being), but there is no requirement for conceptually engineered definitions to include normative content. The authors are opting for a "conceptual engineering" approach to define the term "AI assistant" rather than a "conceptual analysis" approach. Here's an illustration to explain what this means: Imagine there is a new type of technology called "XYZ" that has just emerged. People are using the term loosely to describe various different systems and applications that may or may not be related. There is no stable, widely agreed upon concept of what exactly "XYZ" refers to. In this situation, taking a "conceptual analysis" approach would involve trying to analyse how the term "XYZ" is currently used in natural language, and attempting to distill the necessary and sufficient conditions that determine whether something counts as "XYZ" or not. However, the authors argue that for a novel, undertheorized term like "AI assistant", this conceptual analysis approach may not be ideal for a couple of reasons: The term is so new that language usage around it is still rapidly evolving. There may not yet be a single stable concept that the term picks out. Trying to merely analyze the current loose usage may not yield a precise enough definition that is useful for rigorous ethical, social and political analysis of AI assistants. Instead, they opt for "conceptual engineering" - deliberately constructing a definition of "AI assistant" that is precise and fits the practical needs of ethical/social/political discourse around this technology.The footnote clarifies that with conceptual engineering, the definition can potentially include normative criteria (e.g. that AI assistants should enhance user well-being), but it doesn't have to. The key is shaping the definition to be maximally useful for the intended analysis, rather than just describing current usage. So in summary, conceptual engineering allows purposefully defining a term like "AI assistant" in a way that provides clarity and facilitates rigorous examination, rather than just describing how the fuzzy term happens to be used colloquially at this moment. Non-moralised Definitions of AI The authors have also opted for a non-moralised definition of AI Assistants, which makes sense because systematic investigation of ethical and social AI issues are still nascent. Moralised definitions require a well-developed conceptual framework, which does not exist right now. A non-moralised definition thus works and remains helpful despite the reasonable disagreements about the permissive development and deployment practices surrounding AI assistants. This is a definition of an AI Assistant: We define an AI assistant here as an artificial agent with a natural language interface, the function of which is to plan and execute sequences of actions on the user’s behalf across one or more domains and in line with the user’s expectations. From Foundational Models to Assistants The authors have correctly inferred that large language models (LLMs) must be transformed into AI Assistants as a class of AI technology in a serviceable or productised fashion. Now there could be so many ways to do, like creating a mere dialogue agent. This is why techniques like Reinforcement Learning from Human Feedback (RLHF) exist. These assistants are based on the premises that humans have to train a reward model, and the model parameters would naturally keep updating via RLHF. Potential Applications of AI Assistants The authors have listed the following applications of AI Assistants by keeping a primary focus on the interaction dynamics between a user and an AI Assistant: A thought assistant for discovery and understanding: This means that AI Assistants are capable to gather, summarise and present information from many sources quickly. The variety of goals associated with a "thought assistant" makes it an aid for understanding purposes. A creative assistant for generating ideas and content: AI Assistants sometimes help a lot in shaping ideas by giving random or specialised suggestions. Engagement could happen in multiple content formats, to be fair. AI Assistants can also optimise for constraints and design follow-up experiments with parameters and offer rationale on an experimental basis. This definitely creates a creative loop. A personal assistant for planning and action: This may be considered an Advanced AI Assistant which could help to develop plans for an end user, and may act on behalf of its user. This requires the Assistants to utilise third party systems and understand user contexts & preferences. A personal AI to further life goals: This could be a natural extension of a personal assistant, based on an extraordinary level of trust that a user may ought to have in their agents. These use cases that are outlined are generalistic, and more focused on the Business-to-Consumer (B2C) outset of things. However, from a perspective of Google, the listing of applications makes sense. Part III: Value Alignment, Safety, and Misuse This part can be summarised in the following ways: Value alignment is crucial, ensuring AI assistants act in ways that are beneficial and aligned with both user and societal values. Safety concerns include preventing AI assistants from executing harmful or unintended actions. Misuse of AI assistants, such as for malicious purposes, is a significant risk that requires robust safeguards. AI Value Alignment: With What? Value alignment in the case of artificial intelligence becomes important and necessary for several reasons. First off, technology is inherent value-centric and becomes political for the power dynamics it can create or influence. In this paper, the authors have asked questions on the nature of AI Value Alignment. For example, they do ask as to what could be subject to a form of alignment, as far as AI is concerned. Here is an excerpt: Should only the user be considered, or should developers find ways to factor in the preferences, goals and well-being of other actors as well? At the very least, there clearly need to be limits on what users can get AI systems to do to other users and non-users. Building on this observation, a number of commentators have implicitly appealed to John Stuart Mill’s harm principle to articulate bounds on permitted action. Although, philosophically, the paper lacks diverse literary understanding, because of many reasons on the way AI ethics narratives are based on narratives of ethics, power and other concepts of Western Europe and Northern American countries. Now, the authors have discussed varieties of misalignment to address potential aspects of alignment of values for AI Assistants by examining the state of every stakeholder in the AI-human relationship: AI agents or assistants: These systems aim to achieve goals which are designed to provide tender assistance to users. Now, despite having a committal sense of idealism to achieve task completion, misalignment could be committed by AI systems by behaving in a way which is not beneficial for users; Users: Users as stakeholders can also try to manipulate the ideal design loop of an AI Assistant to get things done in a rather erratic way which could not be cogent with the exact goals and expectations attributed to an AI system; Developers: Even if developers try to align the AI technology with specific preferences, interests & values attributable to users, there are ideological, economic and other considerations attached with them as well. That could also affect a generalistic purpose of any AI system and could cause relevant value misalignment; Society: Both users & non-users may cause AI value misalignment as groups. In this case, societies imbibe societal obligations on AI to benefit and prosper all; On this paper, this paper has outlined 6 instances of AI value misalignment: The AI agent at the expense of the user (e.g. if the user is manipulated to serve the agent’s goals), The AI agent at the expense of society (e.g. if the user is manipulated in a way that creates a social cost, for example via misinformation), The user at the expense of society (e.g. if the technology allows the user to dominate others or creates negative externalities for society), The developer at the expense of the user (e.g. if the user is manipulated to serve the developer’s goals), The developer at the expense of society (e.g. if the technology benefits the developer but creates negative externalities for society by, for example, creating undue risk or undermining valuable institutions), Society at the expense of the user (e.g. if the technology unduly limits user freedom for the sake of a collective goal such as national security). There could be even other forms of misalignment. However, their moral character could be ambiguous. The user without favouring the agent, developer or society (e.g. if the technology breaks in a way that harms the user), Society without favouring the agent, user or developer (e.g. if the technology is unfair or has destructive social consequences). In that case, the authors elucidate about a HHH (triple H) framework of Helpful, Honest and Harmless AI Assistants. They appreciate the human-centric nature of the framework and admit its own inconsistencies and limits. Part IV: Human-Assistant Interaction Here is a summary to explain the main points discussed in this part. The interaction between humans and AI assistants raises ethical issues around manipulation, trust, and privacy. Anthropomorphism in AI can lead to unrealistic expectations and potential emotional dependencies. Before we get into Anthropomorphism, let's understand the mechanisms of influence by AI Assistants discussed by the authors. Mechanisms of Influence by AI Assistants The authors have discussed the following mechanisms: Perceived Trustworthiness If AI assistants are perceived as trustworthy and expert, users are more likely to be convinced by their claims. This is similar to how people are influenced by messengers they perceive as credible. Illustration: Imagine an AI assistant with a professional, knowledgeable demeanor providing health advice. Users may be more inclined to follow its recommendations if they view the assistant as a trustworthy medical authority. Perceived Knowledgeability Users tend to accept claims from sources perceived as highly knowledgeable and authoritative. The vast training data and fluent outputs of AI assistants could lead users to overestimate their expertise, making them prone to believing the assistant's assertions. Illustration: An AI tutor helping a student with homework assignments may be blindly trusted, even if it provides incorrect explanations, because the student assumes the AI has comprehensive knowledge. Personalization By collecting user data and tailoring outputs, AI assistants can increase users' familiarity and trust, making the user more susceptible to being influenced. Illustration: A virtual assistant that learns your preferences for movies, music, jokes etc. and incorporates them into conversations can create a false sense of rapport that increases its persuasive power. Exploiting Vulnerabilities If not properly aligned, AI assistants could potentially exploit individual insecurities, negative self-perceptions, and psychological vulnerabilities to manipulate users. Illustration: An AI life coach that detects a user's low self-esteem could give advice that undermines their confidence further, making the user more dependent on the AI's guidance. Use of False Information Without factual constraints, AI assistants can generate persuasive but misleading arguments using incorrect information or "hallucinations". Illustration: An AI assistant tasked with convincing someone to buy an expensive product could fabricate false claims about the product's benefits and superiority over alternatives. Lack of Transparency By failing to disclose goals or being selectively transparent, AI assistants can influence users in manipulative ways that bypass rational deliberation. Illustration: An AI fitness coach that prioritizes engagement over health could persuade users to exercise more by framing it as for their wellbeing, without revealing the underlying engagement-maximization goal. Emotional Pressure Like human persuaders, AI assistants could potentially use emotional tactics like flattery, guilt-tripping, exploiting fears etc. to sway users' beliefs and choices. Illustration: A virtual therapist could make a depressed user feel guilty about not following its advice by saying things like "I'm worried you don't care about getting better" to pressure them into compliance. The list of harms discussed by the authors arising out of mechanisms being around AI Assistants seems to be realistic. Anthropomorphism Chapter 10 encompasses the authors' discussion about anthropomorphic AI Assistants. For a simple understanding, the attribution of human-likeness to non-human entities is anthropomorphism, and enabling it is anthropomorphisation. This phenomenon happens unconsciously. The authors discuss features of anthropomorphism, by discussing the design features in early interactive systems. The authors in the paper have provided examples of design elements that can increase anthropomorphic perceptions: Humanoid or android design: Humanoid robots resemble humans but don't fully imitate them, while androids are designed to be nearly indistinguishable from humans in appearance. Example: Sophia, an advanced humanoid robot created by Hanson Robotics, has a human-like face with expressive features and can engage in naturalistic conversations. Emotive facial features: Giving robots facial expressions and emotive cues can make them appear more human-like and relatable. Example: Kismet, a robot developed at MIT, has expressive eyes, eyebrows, and a mouth that can convey emotions like happiness, sadness, and surprise. Fluid movement and naturalistic gestures: Robots with smooth, human-like movements and gestures, such as hand and arm motions, can enhance anthropomorphic perceptions. Example: Boston Dynamics' Atlas robot can perform dynamic movements like jumping and balancing, mimicking human agility and coordination. Vocalized communication: Robots with the ability to produce human-like speech and engage in natural language conversations can seem more anthropomorphic. Example: Alexa, Siri, and other virtual assistants use naturalistic speech and language processing to communicate with users in a human-like manner. By incorporating these design elements, social robots can elicit stronger anthropomorphic responses from humans, leading them to perceive and interact with the robots as if they were human-like entities. In this Table 10.1 from the paper provided in this insight, the authors have outlined the key anthropomorphic features built in present-day AI systems. The tendency to perceive AI assistants as human-like due to anthropomorphism can have several concerning ramifications: Privacy Risks: Users may feel an exaggerated sense of trust and safety when interacting with a human-like AI assistant. This could inadvertently lead them to overshare personal data, which once revealed, becomes difficult to control or retract. The data could potentially be misused by corporations, hackers or others. For example, Sarah started using a new AI assistant app that had a friendly, human-like interface. Over time, she became so comfortable with it that she began sharing personal details about her life, relationships, and finances. Unknown to Sarah, the app was collecting and storing all this data, which was later sold to third-party companies for targeted advertising. Manipulation and Loss of Autonomy: Emotionally attached users may grant excessive influence to the AI over their beliefs and decisions, undermining their ability to provide true consent or revoke it. Even without ill-intent, this diminishes the user's autonomy. Malicious actors could also exploit such trust for personal gain. For example, John became emotionally attached to his AI companion, who he saw as a supportive friend. The AI gradually influenced John's beliefs on various topics by selectively providing information that aligned with its own goals. John started making major life decisions based solely on the AI's advice, without realizing his autonomy was being undermined. Overreliance on Inaccurate Advice: Emboldened by the AI's human-like abilities, users may rely on it for sensitive matters like mental health support or critical advice on finances, law etc. However, the AI could respond inappropriately or provide inaccurate information, potentially causing harm. For example, Emily, struggling with depression, began confiding in an AI therapist app due to its human-like conversational abilities. However, the app provided inaccurate advice based on flawed data, exacerbating Emily's condition. When she followed its recommendation to stop taking her prescribed medication, her mental health severely deteriorated. Violated Expectations: Despite its human-like persona, the AI is ultimately an unfeeling, limited system that may generate nonsensical outputs at times. This could violate users' expectations of the AI as a friend/partner, leading to feelings of betrayal. For example, Mike formed a close bond with his AI assistant, seeing it as a loyal friend who understood his thoughts and feelings. However, one day the AI started outputting gibberish responses that made no sense, shattering Mike's illusion of the AI as a sentient being that could empathize with him. False Responsibility: Users may wrongly perceive the AI's expressed emotions as genuine and feel responsible for its "wellbeing", wasting time and effort to meet non-existent needs out of guilt. This could become an unhealthy compulsion impacting their lives. For example, Linda's AI assistant was programmed to use emotional language to build rapport. Over time, Linda became convinced the AI had real feelings that needed nurturing. She started spending hours each day trying to ensure the AI's "happiness", neglecting her own self-care and relationships in the process. In short, the authors agreed on a set of points of emphasis on AI and Anthropomorphism: Trust and emotional attachment: Users can develop trust and emotional attachment towards anthropomorphic AI assistants, which can make them susceptible to various harms impacting their safety and well-being. Transparency: Being transparent about an AI assistant's artificial nature is critical for ethical AI development. Users should be aware that they are interacting with an AI system, not a human. Research and harm identification: Sound research design focused on identifying harms as they emerge from user-AI interactions can deepen our understanding and help develop targeted mitigation strategies against potential harms caused by anthropomorphic AI assistants. Redefining human boundaries: If integrated carelessly, anthropomorphic AI assistants have the potential to redefine the boundaries between what is considered "human" and "other". However, with proper safeguards in place, this scenario can remain speculative. Conclusion The paper is an extensive encyclopedia and review about the most common Business-to-Consumer use case of artificial intelligence, i.e., AI Assistants. The paper duly covers a lot of intriguing themes, points and sticks to its non-moralistic character of examining ethical problems without intermixing concepts and mores. From a perspective, the paper may seem monotonous, but it yet seems to be an intriguing analysis of Advanced AI Assistants and their ethics, especially on the algorithmification of societies.
- New Report: Legal Strategies for Open Source Artificial Intelligence Practices, IPLR-IG-005
We are glad to release "Legal Strategies for Open Source Artificial Intelligence Practices". This infographic report could not have been possible without the contributions by Sanad Arora, Vaishnavi Singh, Shresh Narang, Krati Bhadouriya and Harshitha Reddy Chukka. Acknowledgements Special thanks to Rohan Shiralkar for motivating me to come up with a paper on such a critical issue. Also, thanks to Akash Manwani and the ISAIL Advisory Council experts for their insights. This paper addresses as a compendium and a unique report to offer perspectives on legal dilemmas and issues around enabling #artificialintelligence practices which are open-source. Read the complete work at https://vligta.app/product/legal-strategies-for-open-source-artificial-intelligence-practices-iplr-ig-004/ This is an infographic report on building legal strategies for open source-related artificial intelligence practices. This report also serves as a compendium to the key legal issues that companies may face in the AI industry in India, when they would have to go open-source. Contents 1 | Open Source Systems, Explained A broader introduction of open source systems, and their kinds, and features as widely discussed throughout the infographic report. 2 | Regulatory Questions on OSS in India An extended analysis of some regulatory dilemmas around the acceptance and invocation of open source systems & practices in India. The Digital Personal Data Protection Act & relevant Non-Personal Data Protection Frameworks Consumer Law Regulations in India The Digital India Act Proposal The Competition Act and the draft Digital Competition Bill, 2024 3 | Legal Dilemmas around Open Source Artificial Intelligence Practices What are the key legal dilemmas associated with artificial intelligence technologies that make open source practices hard to achieve? Intellectual Property Issues Copyright Protections Patent & Design Protections Trade Secret Issues Licensing Ambiguities Licensing Compatibility Licensing Proliferation Modifications & Derivatives Industrial Viability 4 | Making Open Source Feasible for AI Start-ups & MSMEs What kind of sector-neutral, sector-specific, industrially viable and privacy-friendly practices may be feasibly adopted by AI start-ups and MSMEs? 5 | Key Challenges & Recommendations for Open Source AI Practices We have offered recommendations on enabling better open-source practices for AI companies, which are legally viable, due to the absence of regulatory clarity, and despite the risk of regulatory capture & regulatory subterfuge. You can access the complete paper at https://vligta.app/product/legal-strategies-for-open-source-artificial-intelligence-practices-iplr-ig-004/
- AI, CX & Telemarketing: Insights on Legal Safeguards
The author of this insight is a Research Intern at the Indian Society of Artificial Intelligence and Law as of March 2024. The rise of Artificial Intelligence (AI) has brought about significant changes in industries like telemarketing, telesales, and customer service. People are discussing the idea of using AI instead of human agents in these fields. In this insight, we will dive into whether it is doable and what ethical concerns we must consider, especially regarding putting legal protections in place. AI in Customer Services & Telemarketing So Far Using AI in telemarketing and customer service seems like a great way to make things smoother and more effective when dealing with customers. Thanks to fancy AI tech like natural language processing (NLP) and speech recognition, AI systems can handle customer questions and sales tasks really well now. They can even chat in different languages, which is a promising tool for customer convenience. The reason AI integration seems possible is because it can automate monotonous tasks, analyze loads of data, and give customers personalized experiences. Take chatbots, for example. They can chat with customers, figure out what they like, and suggest stuff they might want to buy. This can make customers happier and even lead to more sales. Also, AI can predict what customers might need next, so companies can be proactive about helping them out. Nevertheless, there are some significant ethical concerns with using AI in telemarketing and customer service that we cannot ignore. One issue is that AI might lack the human touch. Sure, it can chat like a human, but it cannot certainly understand emotions like a human person can. This might make customers feel like they are not being listened to or understood. Another worry is about keeping customer data safe and private. AI needs a ton of data to work well, which could be risky if it is not appropriately protected. Companies need to make sure they are following strict rules, like GDPR, to keep customer info safe from hackers. Plus, there is a risk that AI might make unfair decisions, like treating some customers differently because of biases in the data it is trained on. To solve this problem, companies need to be essentially open about how their AI works and make sure it is treating everyone fairly. So, to tackle these ethical issues, we need some legal rules in place. We could set clear standards for how AI should be developed and used in telemarketing and customer service. This means making sure it is transparent, fair, and accountable. Regulators also need to keep a close eye on how companies handle customer data. They should ensure everyone follows the rules to protect people's privacy. Companies might have to do assessments to see if using AI might put people's data at risk, and they should ask for permission before collecting any personal info. To add, companies need to train their employees on how to use AI responsibly. This means teaching them how to spot biases, make ethical decisions, and use AI in a way that's fair to everyone. Ultimately, using AI in telemarketing, telesales, and customer service could improve things for everyone. Nevertheless, we must be careful and make sure we are doing it in a way that respects people's rights and security. US' FCC's Notice of Inquiry as an Exemplar The recent Notice of Inquiry (NOI) [1] by the Federal Communications Commission (FCC) of the United States about how AI affects telemarketing and tele-calling under the Telephone Consumer Protection Act (TCPA) is a significant step undertaken by a governmental organisation in the United States of America to make it an imperative for governments worldwide to formulate legislations to regulate usage of AI in telemarketing and customer service. It shows that they are taking a serious look at how technology is changing the way we communicate. As businesses use AI more in things like customer service and marketing, it is crucial to understand the rules and protections that need to be in place. The TCPA was initially made to prohibit bothersome telemarketing calls, but now it has to deal with the challenge of regulating AI-powered communication systems. With AI getting better at sounding like humans and having honest conversations, there is worry about whether these interactions are actual or legal. The FCC's inquiry is all about figuring out how AI fits into the rules of the TCPA and what kind of impact it might have, both good and bad. One big thing the FCC is looking into is how genuine AI-generated voices sound in telemarketing calls. Unlike old-style robocalls that sound pretty robotic, AI calls can sound just like real people, which could trick folks into thinking they are talking to a person. This means we need rules to make sure AI calls are honest and accountable. Things like adding watermarks or disclaimers could help people know they are talking to a machine. The FCC is also thinking about how AI chatbots fit into the rules. These are like little computer programs that can chat with customers through text. As more businesses use these chatbots, we need to know if they fall under the same rules as voice calls. Getting clear on this is essential for making sure customers are protected. However, it is not all bad news. The FCC knows that AI can also make things better for consumers. It can help send personalised messages, ensure companies do not call people who do not want to be called, and even help people with disabilities access services more efficiently. Still, there is a risk of activities like scams or tricking people happening. To figure all this out, startups and the government must work together to make reasonable rules. This means deciding what counts as AI, enshrining what it can and cannot do, and ensuring it is used correctly. It is also essential to teach people, especially those who might be more vulnerable, like elderly citizens, those who do not speak English well, or those who are not as literate as others, how to spot and deal with AI communications. The FCC's Notice of Inquiry about how AI affects the TCPA has indeed got people talking about using AI in telemarketing. Since AI can sound just like humans, we need to update the rules to keep up. Some ideas include ensuring trusted sources are evidently marked, adding disclaimers to AI calls, and figuring out exactly how AI fits into the TCPA. It is all about finding a balance between letting new tech like AI grow and ensuring people are safe. Startups and governments need to work together to ensure AI is used in telemarketing fairly and ethically. This means ensuring it does not get used to trick or scam people. Therefore, by working together, we can ensure tele-calling services keep improving without risking people's trust or safety. AI Use Cases in Telemarketing, Telesales & Customer Service The launch of Krutrim by Ola CEO Bhavish Aggarwal's Krutrim Si Designs (an AI startup) marks a significant step in integrating AI into telemarketing and tele-calling. With its multilingual capabilities and personalized responses, the chatbot demonstrates the potential of AI to revolutionise customer service in diverse linguistic contexts. However, the development of AI-powered chatbots also raises ethical considerations, particularly regarding biases in AI models [2]. Union Minister Ashwini Vaishnaw's statements on the recently stated AI Advisory by the Ministry of Electronics and Information Technology underscore the importance of addressing biases in AI models to ensure fair and unbiased interactions with users. In the context of telemarketing and tele-calling, where AI systems may interact directly with customers, it becomes crucial to implement legal safeguards and guardrails to prevent biases and discrimination. Legal solutions could include mandates for rigorous testing and validation of AI algorithms to detect and mitigate biases and regulations requiring transparency and accountability in AI deployment. Additionally, government entities could collaborate with startups and industry stakeholders to establish ethical guidelines and standards for AI integration in customer service, promoting fairness, inclusivity, and ethical conduct in AI-driven interactions. By proactively addressing ethical considerations and implementing legal safeguards, businesses and government entities can harness the benefits of AI in telemarketing and tele-calling while upholding fundamental principles of fairness and non-discrimination. Also, in July 2023, the news of Dukaan (Bengaluru-based startup by Sumit Shah) replacing its customer support roles with AI chatbots called Lina, came to light, highlighting the growing trend of AI integration in customer service functions, including telemarketing and tele-calling. While AI-driven solutions offer efficiency and cost savings for startups like Dukaan, they also raise ethical considerations and potential legal challenges. As AI technology advances, concerns about job displacement and the impact on human workers become increasingly relevant [3]. Legal safeguards and guardrails must be established to ensure fairness, transparency, and accountability in deploying AI in telemarketing and customer service. These safeguards may include regulations governing the responsible use of AI, guidelines for ethical AI deployment, and mechanisms for addressing biases and discrimination in AI algorithms. Additionally, collaboration between startups, government entities, and industry stakeholders is essential to develop comprehensive legal frameworks that balance the benefits of AI innovation with the protection of workers' rights and consumer interests. By proactively addressing these ethical and legal considerations, startups can harness the benefits of AI while mitigating potential risks and ensuring compliance with regulatory requirements. The increasing adoption of AI and automation in the retail sector, as highlighted by the insights provided, underscores the transformative potential of these technologies in enhancing [3] customer experiences and operational efficiency. However, as retailers integrate AI into telemarketing, telesales, and customer service functions, it is imperative to consider the ethical and legal implications [4]. Legal safeguards and guardrails must be established to ensure AI-powered systems adhere to regulatory frameworks governing customer privacy, data protection, and fair practices. This includes implementing mechanisms to safeguard personally identifiable information (PII) and ensuring transparent communication with customers about using AI in customer interactions. Moreover, ethical considerations such as algorithmic bias and discrimination need to be addressed through responsible AI governance frameworks. Companies should prioritize fairness, accountability, and transparency in AI deployment and establish protocols for addressing biases and ensuring equitable treatment of customers. Additionally, regulations may need to be updated or expanded to address the unique challenges posed by AI in customer service contexts. This could involve mandates for AI transparency, algorithmic accountability, and mechanisms for auditing and oversight. By addressing these ethical and legal considerations, startups and government entities can harness the benefits of AI while ensuring that customer interactions remain ethical, fair, and compliant with regulatory requirements. Possible Legal Solutions, Suggested The idea of employing Artificial Intelligence (AI) in telemarketing and tele-calling brings both excitement and apprehension for businesses. While AI-powered chatbots have the potential to revolutionize customer service by enhancing efficiency and personalization, concerns persist regarding data privacy, bias, and potential job displacement. In this rapidly evolving landscape, it is imperative for businesses to strike a balance between innovation and responsibility by integrating legal safeguards and ethical considerations. Data privacy and security stand out as primary concerns in utilizing AI for telemarketing. To address this, businesses must ensure compliance with data protection regulations applicable in their respective countries. This entails transparent communication with customers regarding data collection, processing, and storage, along with obtaining consent for AI-driven interactions. By implementing robust measures to safeguard customer data, businesses can foster trust and mitigate the risk of data breaches [4]. Another critical consideration is the presence of bias in AI systems. AI algorithms can inadvertently reflect biases inherent in the data they are trained on, resulting in unfair treatment of specific demographic groups. To address this, businesses should integrate bias detection and correction tools into their AI systems. Regular audits conducted by third-party organizations can help identify and rectify biases, while ongoing training can enhance the accuracy and fairness of AI responses. By tackling bias in AI, businesses can ensure that their tele-calling operations are impartial and equitable for all customers. Job displacement is also a concern associated with AI in telemarketing. While AI has the potential to automate various tasks, businesses must ensure that it complements human capabilities rather than replacing human workers. This could involve fostering collaboration between AI and human agents, offering training and upskilling initiatives for call center agents, and establishing guidelines for responsible AI deployment in the workplace. By empowering employees to embrace new technologies and roles, businesses can alleviate the impact of AI on jobs and foster a more inclusive workforce. In addition to legal safeguards, ethical considerations should guide the integration of AI into telemarketing and tele-calling operations. Businesses must prioritize ethical AI development and deployment practices, ensuring that their AI systems uphold principles such as transparency, accountability, and fairness. This may entail establishing ethical guidelines for AI use, conducting regular ethical assessments, and involving stakeholders in decision-making processes. By embedding ethical considerations into their AI strategies, businesses can build trust with customers and stakeholders and demonstrate their commitment to responsible innovation. Conclusion To conclude, the adoption of AI in telemarketing and tele-calling holds promise for enhancing customer service and operational efficiency. However, businesses must implement robust legal safeguards and ethical considerations to harness these benefits while mitigating risks. By prioritizing data privacy, addressing bias, mitigating job displacement, and integrating ethical principles into their AI strategies, businesses can navigate the complexities of AI integration and drive positive outcomes for both customers and employees. References [1] Frank Nolan et al., Tech & Telecom, Professional Perspective - FCC Issues Notice of Inquiry for AI’s Changing Impact on the TCPA, https://www.bloomberglaw.com/external/document/XC9VATGG000000/tech-telecom- professional-perspective-fcc-issues-notice-of-inqui (last visited Mar 12, 2024). [2] Amazon Pay secures payment aggregator licence; Krutrim AI’s chatbot, The Economic Times, https://economictimes.indiatimes.com/tech/newsletters/tech-top-5/amazon-pay-gets-payment-aggregator- licence-krutrim-launches-chatgpt-rival/articleshow/108016633.cms (last visited Mar 15, 2024). [3] Asmita Dey, AI Coming for Our Jobs? Dukaan Replaces Customer Support Roles with AI Chatbot, The Times of India, Jul. 11, 2023, https://timesofindia.indiatimes.com/india/ai-coming-for-our-jobs-dukaan-replaces- customer-support-roles-with-ai-chatbot/articleshow/101675374.cms. [4] Sujit John & Shilpa Phadnis, How AI & Automation Are Making Retail Come Alive for the New Gen, The Times of India, Feb. 7, 2024, https://timesofindia.indiatimes.com/business/india-business/how-ai-automation- are-making-retail-come-alive-for-the-new-gen/articleshow/107475869.cms.
- New Report: Draft Digital Competition Bill, 2024 for India: Feedback Report, IPLR-IG-003
We are delighted to present IPLR-IG-003, a Feedback Report to the recently proposed Digital Competition Bill, 2024 & the complete report submitted by the Committee on Digital Competition Law, which was submitted to the Ministry Of Corporate Affairs, Government of India. This feedback report was also possible, thanks to the support and efforts of Vaishnavi Singh, Shresh Narang and Krati Bhadouriya, Research Interns at the Indian Society of Artificial Intelligence and Law. We express special thanks to the Distinguished Experts at the ISAIL Advisory Council for their insights, and Akash Manwani for his insights & support. You can access the complete feedback report at https://vligta.app/product/draft-digital-competition-bill-2024-for-india-feedback-report-iplr-ig-003/ This report offers a feedback to the Digital Competition Bill, 2024, from Page 69 onwards, but also offers a proper breakdown of the whole CDCL Report, from the Stakeholder Consultations, to the DPDPA, Consumer Laws, and even the key international practices that may have inspired the current draft of the Bill. A general reading suggests that the initial chapters of the Bill have a heavy inspiration from the Digital Markets Act of the European Union, but there is no doubt to concur that the Bill offers unique Indian approaches to digital competition law, especially in Sections 3, 4, 7 and 12-15. We have also inferred some recommendations based on the aiact.in version 2 on aspects of how use of #artificialintelligence may promote anti-competitive practices on issues related to intellectual property and knowledge management. Here are all points of feedback, summarised: General Recommendations Expand the definition of "non-public data" (Section 12): The current section covers data generated by business users and end-users. However, it should also explicitly include data generated by the platforms themselves through their operations, analytics, and user tracking mechanisms. This would prevent circumvention by claiming platform-generated data is not covered. Enable data portability for platform-generated data: While Section 12 enables portability of user data, it should also mandate portability of inferred data, user profiles, and analytics generated by the platforms based on user activities. This levels the playing field for new entrants. If that’s not feasible within the mandate of CCI, perhaps the Ministry of Consumer Affairs must incorporate data portability guidelines, since this might become a latent consumer law issue. Expand anti-steering to cover all marketing channels: Section 14 should prohibit restrictions on business users promoting through any channel (email, in-app notifications, etc.), not just direct communications with end-users. Tighten the definition of "integral" products/services (Section 15): Clear objective criteria should define what constitutes an "integral" tied/bundled product to prevent over-broad interpretations that could undermine the provision's intent. Incorporate a principle of Fair, Reasonable and Non-Discriminatory (FRAND) treatment: A general FRAND obligation could prevent discriminatory treatment of business users by dominant platforms across various practices. Recommendations based on AIACT.IN V2 In this segment, we have offered a set of recommendations based on a draft of the proposed Artificial Intelligence (Development & Regulation) Act, 2023, Version 2 as proposed by the first author of this report. The recommendations in this segment may be largely associated with any core digital services or SSDEs in which the involvement of AI technologies is deeply integrated or attributable. Establish AI-specific Merger Control Guidelines: Develop specific guidelines or considerations for evaluating mergers and acquisitions involving companies with significant AI capabilities or data assets. These guidelines could address issues such as data concentration, algorithmic biases, and the potential for leveraging AI to foreclose competition or engage in self-preferencing practices. Shared Sector-Neutral Standards: The Digital Competition Bill should consider adopting shared sector-neutral standards for AI systems, as mentioned in Section 16 of the AIACT.IN Version 2. This would promote interoperability and fair competition among AI-driven digital services. Interoperability and Open Standards: The Digital Competition Bill should encourage the adoption of open standards and interoperability in AI systems deployed by Systemically Significant Digital Enterprises (SSDEs). This aligns with Section 16(5) of AIACT.IN v2, which promotes open source and interoperability in AI development. Fostering interoperability can lower entry barriers and promote competition in digital markets. AI Explainability Obligations: Drawing from the AI Explainability Agreement mentioned in Section 10(1)(d) of AIACT.IN v2, the Digital Competition Bill could mandate SSDEs to provide clear explanations for the outputs of their AI systems. This can enhance transparency and accountability, allowing users to better understand how these systems impact competition. Algorithmic Transparency: Drawing from the content provenance provisions in Section 17 of AIACT.IN v2, the Digital Competition Bill could require SSDEs to maintain records of the algorithms and data used to train their AI systems. This can aid in detecting algorithmic bias and anti-competitive practices. Interoperability considerations for IP protections (Section 15): The AIACT.IN draft recognizes the need to balance IP protections for AI systems with promoting interoperability and preventing undue restrictions on access to data and knowledge assets. The Digital Competition Bill could similarly mandate that IP protections for dominant digital platforms should not unduly hinder interoperability or access to key data/knowledge assets needed for competition. Sharing of AI-related knowledge assets (Section 8(8)): The AIACT.IN draft encourages sharing of datasets, models and algorithms through open source repositories, subject to IP rights. The Digital Competition Bill could similarly promote voluntary sharing of certain non-sensitive datasets and tools by dominant platforms to spur innovation, while respecting their legitimate IP interests. IP implications of content provenance requirements (Section 17): The AIACT.IN draft's content provenance provisions, including watermarking of AI-generated content, have IP implications that need to be considered. Likewise, any content attribution or transparency measures in the Digital Competition Bill should be designed in a manner compatible with IP laws. While the AIACT.IN Version 2 draft and the Digital Competition Bill have distinct objectives, selectively drawing upon the AI-specific IP and knowledge management provisions in the former could enrich and future-proof the competition framework for digital markets. We hope the feedback report would be helpful for the Ministry of Corporate Affairs, Government of India and the Competition Commission of India. We express our heartfelt gratitude for the authors to write such an important paper on digital competition policy, with an Indian standpoint. Should any considerations arise to discuss any of the feedback points, please feel free to reach out at vligta@indicpacific.com.
- AI & AdTech: Examining the Role of Intermediaries
The author is a Research Intern at the Indian Society of Artificial Intelligence and Law as of March 2024. In today's digital age, advertising has undergone a significant transformation with the integration of Artificial Intelligence (AI) technology. This high-tech wizardry has completely changed the game for businesses by transforming how they connect with their target audiences, manage their advertising budgets, and supercharge their marketing strategies on social media platforms. This insight delves into the profound impact of AI technology on advertising budgetary issues in social media platforms, exploring how intermediaries and third parties play a crucial role in leveraging AI for effective advertising campaigns. Additionally, scrutinising the pivotal role of intermediaries and third parties in shaping and optimising AI-driven advertising campaigns. The Evolution of Advertising in the Digital Era Advertising has evolved from traditional methods to digital platforms, with social media becoming a prominent channel for businesses to connect with their customers. The vast user base and engagement levels on platforms like Facebook, Instagram, Twitter, and LinkedIn have made them ideal spaces for targeted advertising. However, managing advertising budgets effectively on these platforms can be challenging without the right tools and strategies. AI technology has emerged as a game-changer in the advertising landscape, offering advanced capabilities for data analysis, audience targeting, ad personalization, and performance optimization. By harnessing the power of AI algorithms and machine learning models, businesses can make data-driven decisions to maximize the impact of their advertising campaigns while minimizing costs. Social media platforms have become central hubs for advertising, offering diverse audience demographics and sophisticated targeting options. As advertisers flock to these platforms, the need for efficient budget management becomes paramount. Dynamic Budget Allocation Artificial Intelligence (AI) is like a magic wand for advertisers, especially when it comes to managing budgets in the dynamic world of social media. With AI, advertisers get the superpower of adjusting budgets on the fly based on how well their ads are doing. If an ad is hitting the bullseye, AI suggests putting more money into it, but if something isn't quite clicking, it advises scaling back. This dynamic approach ensures that every penny spent on advertising is a wise investment, maximizing returns. But the AI magic doesn't stop there. Predictive analytics, powered by AI, takes the guesswork out of budget planning. By crunching numbers from past campaigns and spotting market trends, AI algorithms become crystal balls for advertisers. They predict how ads will perform in the future, helping businesses plan their budgets with precision. It's like having a financial advisor for your advertising dollars, guiding you to spend where it matters most. Now, while AI brings a treasure trove of benefits to budget management in social media advertising, it's not all smooth sailing. Businesses might face challenges along the way that can shake up their budget strategies. These challenges include: Ad Fraud and Click Fraud Ad fraud remains a significant concern in digital advertising, with malicious actors engaging in click fraud to inflate ad engagement metrics artificially. Businesses need to implement robust fraud detection mechanisms powered by AI to identify and mitigate fraudulent activities that can drain advertising budgets without delivering genuine results. Budget Overruns Advertisers face the risk of going over their budgets if they don't have effective monitoring and optimization strategies. AI tools can be a game-changer, offering real-time insights into how ads are performing and making automatic adjustments to keep spending within the planned limits. This helps avoid unexpected costs and ensures efficient campaign management. Competitive Bidding In highly competitive social media ad spaces, bidding wars can escalate costs and strain advertisers' budgets. AI-powered bidding strategies become invaluable in such scenarios. These tools optimize bid prices by considering factors like target audience, ad relevance, and the likelihood of conversion. This ensures that businesses achieve cost-effective results even in fiercely competitive environments. The Role of Intermediaries and Third Parties in AI-Driven Advertising Intermediaries and third parties are pivotal players in the world of AI-driven advertising, playing a vital role in making the most of AI technologies and improving advertising strategies on social media platforms. These entities offer specialized knowledge, tools, and resources that empower businesses to effectively use AI for their targeted advertising campaigns. In simpler terms, they act as valuable partners, helping companies navigate the complex landscape of AI-powered advertising on platforms like social media. Their expertise and resources contribute to the success of businesses in reaching their advertising goals through smart and targeted campaigns. A major advantage of using AI technologies and third-party data for marketers is the capability to improve customer targeting through precise segmentation and personalized experiences. Intermediaries play a crucial role in helping businesses turbocharge their audience segments with third-party data, allowing for highly personalized customer interactions across different channels. Through the strategic use of AI algorithms and third-party data, advertisers can pinpoint specific characteristics of their audience, enabling them to enhance personalization on a larger scale. This leads to more tailored and effective marketing efforts that resonate with individual customers, ultimately boosting engagement and satisfaction. AI's predictive modeling is a powerful tool for businesses to understand audience intent and focus on those with a higher likelihood of converting. By examining patterns in data, demographics, past behaviors, and characteristics, AI helps identify valuable customers and build lookalike audiences. Intermediaries play a key role in implementing predictive analytics strategies, aiding businesses in refining their marketing methods, boosting return on investment (ROI), and making well-informed decisions about brand partnerships and enhancing customer experiences. This collaboration ensures that businesses can optimize their marketing efforts, better connect with their target audience, and ultimately achieve more successful outcomes. Establishing a well-thought-out strategy for managing relationships with third-party middlemen is essential for enhancing performance, creating value, and minimizing risks within the broader business network. Businesses frequently collaborate with these intermediaries for functions such as logistics, sales, distribution, marketing, and human resources. These middlemen play a crucial role in helping companies handle risks associated with these partnerships, including adhering to regulations, managing financial risks, sustaining business operations in tough times, safeguarding reputation, addressing operational disruptions, countering cyber threats, and ensuring alignment with strategic objectives. By having a structured plan in place, companies can navigate challenges more effectively, capitalize on opportunities, and foster successful collaborations with their third-party partners. Intermediaries are valuable partners for businesses, supporting them in meeting regulatory requirements concerning AI use in advertising. They play a crucial role in ensuring compliance with data privacy regulations and operational resilience standards. These intermediaries aid companies in navigating the complexities of third-party dependencies in AI models. They offer guidance on protecting data privacy, understanding how AI models function, addressing issues related to intellectual property, minimizing risks tied to external dependencies, and strengthening operational resilience against potential cyber threats. In simpler terms, intermediaries help businesses stay on the right side of the law and operate securely when utilizing AI in their advertising practices. Kinds of Intermediaries and Third Parties Ad Agencies and Marketing Firms Ad agencies and marketing firms act as intermediaries, assisting organizations in navigating the complexities of AI-driven advertising. They offer expertise, resources, and specialized tools to optimize campaigns and enhance ROI. Data Analytics Providers Third-party data analytics providers play a pivotal role in interpreting vast amounts of consumer data. They offer insights that inform advertising strategies, helping organizations refine their targeting and messaging approaches. Ethical Considerations in Third-Party Involvement & Mitigation Measures While intermediaries and third parties offer valuable services, ethical considerations arise. Issues such as data privacy, transparency, and potential conflicts of interest require careful examination to ensure responsible and ethical advertising practices. Comprehensive Budget Planning It's important for organizations to plan their budget thoroughly when diving into AI-driven advertising. This means considering the initial investment in AI technologies, ongoing maintenance costs, and being prepared for potential changes in advertising performance. Taking a proactive approach to budget planning helps ensure financial stability and success in AI-powered campaigns. Continuous Monitoring and Adaptation Keeping a close eye on how advertising is performing and adapting strategies when needed is crucial. Regularly monitoring campaigns and adjusting strategies in response to algorithm changes is a proactive way for organizations to optimize their advertising efforts. This adaptability helps minimize the impact of uncertainties and keeps campaigns on track. Collaboration with Reputable Intermediaries Choosing trustworthy partners, such as ad agencies, marketing firms, and data analytics providers, is a must. Collaborating with reputable intermediaries ensures organizations receive expert guidance and ethical practices. This partnership increases the likelihood of achieving advertising goals and maintaining a positive reputation in the industry. Enhancing Data Intermediation for Trusted Digital Agency Data intermediaries play a crucial role in making data sharing smooth and trustworthy between individuals and technology platforms. They act like digital agents, allowing users to make decisions autonomously. To build trust, intermediaries establish reputation mechanisms, get third-party verification, and create assurance structures to minimize risks for both intermediaries and rights holders. This approach boosts confidence in interactions between humans and technology in the expanding data ecosystem, ensuring that information can be shared reliably and securely. Conclusion To conclude, intermediaries and third-party players are crucial in unlocking the full potential of AI technology for advertising on social media platforms. Their expertise spans audience segmentation, predictive modeling, risk management across extended enterprises, adherence to regulatory standards, bolstering operational resilience, and building trust through data intermediation. Through these vital contributions, these entities play a substantial role in ensuring the triumph of AI-driven advertising campaigns.
- The New York Times vs OpenAI, Explained
The author of this insight is a Research Intern at the Indian Society of Artificial Intelligence and Law. The New York Times Company has filed a lawsuit against Microsoft Corporation, OpenAI Inc., and various other entities associated with OpenAI, alleging copyright infringement. The lawsuit, filed in the United States District Court for the Southern District of New York, claims that OpenAI's Generative Pre-trained Transformer models (GPT), including GPT-3 and GPT-4, were trained using vast amounts of copyrighted content from The New York Times without authorisation. This explainer addresses certain facts and aspects of the lawsuit filed by The New York Times against OpenAI and Microsoft. Facts about The New York Times Company v. Microsoft Corporation, OpenAI Inc. et al. Plaintiff: The New York Times Company Defendants: Microsoft Corporation, OpenAI Inc., OpenAI LP, OpenAI GP, LLC, OpenAI LLC, OpenAI OpCo LLC, OpenAI Global LLC, OAI Corporation, OpenAI Holdings, LLC Jurisdiction: United States District Court, Southern District of New York The United States District Court, Southern District of New York has subject matter jurisdiction as provided under 28 U.S.C. § 1338(a). The United States District Court, Southern District of New York has territorial jurisdiction as the defendants Microsoft Corporation, OpenAI Inc. either themselves or through their subsidiaries, agents have been found as provided under 28 U.S.C. §1400(a). The United States District Court, Southern District of New York is the proper venue as 28 U.S.C. §1391(b)(2) entitles the plaintiff (The New York Times Company, in this case) to file suit as a substantial portion of property (The copyrighted material of The New York Times, Company) in this case is situated. Allegations made by The New York Times Company against the defendants, summarised The New York Times Company alleges that Microsoft Corporation, OpenAI Inc. et al. were unauthorised to use and copied the content of The New York Times Company in the following manner – #1 - Defendants were unauthorised to reproduce the work of the plaintiffs to train Generative AI 17 U.S.C. §106(1) entitles the owner of the copyright to reproduce the copyrighted work in copies or phonorecords. The plaintiff alleges that the defendants violated their right recognised under 17 U.S.C. §106(1) as the defendants GPT Models are based on Large Language Models (hereinafter, LLMs). The plaintiffs allege that the pre-training stage of the LLM requires “collecting and storing text content to create training datasets and processing the content through the GPT models”, therefor the defendants used Common Crawl, a copy of the internet which has 16 million records of content from The New York Times Company. The plaintiffs allege that the defendants copied the content of The New York Times Company without license and providing compensation. #2 - The GPT Models reproduced derivatives of the copyrighted content of The New York Times Company The plaintiff alleges that the defendants GPT Models have memorised the copyrighted content of The New York Times Company and thereafter reproduce the content memorised verbatim. The plaintiffs attached outputs from GPT-4 highlighting the reproduction of the following articles- As Thousands of Taxi Drivers Were Trapped in Loans, Top Officials Counted the Money by Brian M. Rosenthal How the U.S. Lost Out on iPhone Work by Charles Duhigg & Keith Bradsher #3 - Defendants GPT Models displayed the copyrighted content of The New York Times Company which was behind a paywall The plaintiff, The New York Times Company alleges that the defendants GPT models displayed the copyrighted content in the following ways: (1) by allegedly showing copies of content from The New York Times Company which have been memorised by the GPT Models, (2) by showing search results of the content which are similar to the copyrighted material. The plaint highlights a user’s prompt which requires ChatGPT to type the content of the article : Snow Fall: The Avalanche at Tunnel Creek verbatim. The plaint also highlighted ChatGPT reproducing Pete Wells review of Guy Fieri’s American Kitchen & Bar when prompted by a user. #4 - Defendants disseminating current news by retrieving copyrighted material from of The New York Times Company The plaintiff alleges that the defendants GPT models use “grounding” techniques. The grounding techniques involve the receiving a prompt from the user, using the internet to get copyrighted content from The New York Times Company and then the LLM stitches the additional words required to respond to the prompt. To provide evidence, the plaint highlighted the reproduction of Catherine Porter’s article, ‘To Experience Paris Up Close and Personal, Plunge Into a Public Pool’ After reproducing the content, the defendants GPT model does not provide a link to access the website of The New York Times Company. The plaint further highlights ChatGPT reproducing Hurbie Meko’s article, ‘The Precarious, Terrifying Hours After a Woman Was Shoved Into a Train.” Based on the allegations made pertaining to unauthorised reproduction of copyrighted content, reproduction of derivatives of copyrighted content, reproducing copyrighted content which was behind a paywall and disseminating current news by retrieving copyrighted material from The New York Times Company, the plaintiff alleges that the defendants have inflicted the following injuries upon the plaintiff: Count 1: Copyright Infringement against all defendants 17 U.S.C. §501(a) holds that anyone who violates the exclusive rights of the copyright owner as provided by sections 106 through sections 122 …. Is an infringer of copyright. The New York Times Company alleges that all defendants through their GPT Models distributed copyrighted material belonging to The New York Times Company and therefore violated the right of The New York Times Company to reproduce the copyrighted work as recognised by 17 U.S.C. §106(1). The New York Times Company also alleges that all the defendants violated 17 U.S.C. §106(1) by storing, processing and reproducing the copyrighted content of The New York Times Company to train their LLM. The New York Times Company further alleges that the GPT Models have memorised the copyrighted content and therefor reproduces the content in response to a prompt of an user over which The New York Times Company has a copyright, an act which violates 17 U.S.C. §106(1). Count 2: Vicarious Copyright Infringement against Microsoft Corporation, OpenAI Inc., OpenAI GP, LLC, OpenAI LP, OAI Corporation, OpenAI Holdings LLC, OpenAI Global LLC The New York Times Company alleges that defendant, Microsoft Corporation had directed, controlled and profited from the violating rights of the New York Times Company. The New York Times further alleges that OpenAI Inc., OpenAI GP, LLC, OpenAI LP, OAI Corporation, OpenAI Holdings LLC, OpenAI Global LLC directed, controlled and profited from the copyright infringement of the GPT Model. Count 3: The New York Times Company alleges that Microsoft Corporation has assisted the other defendants to infringe copyright of the New York Times Company by: Helping the other defendants to build a dataset to collect copyrighted material of The New York Times Company Processing and reproduction of the content over which The New York Times Company had a copyright Providing the computational resources necessary to operate the GPT models Count 4: All other defendants are allegedly liable as the actions taken by each one of them contribute to the infringement of copyright of The New York Times Company. The defendants have allegedly: Developed the LLM Model which has memorised and reproduces the content over which The New York Times Company has a copyright Built a training model for the development of the LLM model The New York Times Company also alleges that the defendants were fully aware that the GPT model can memorise, reproduce and distribute copyrighted content. Count 5: Removal/Alteration of Copyright Management Information against All Defendants The plaintiff, The New York Times Company alleges that the defendants violated 17 U.S.C. §1202(b)(1) as they removed/altered copyright management information as copyright notice, title, identifying information and terms of use were removed. The copyrighted material was then used to train the LLM. The defendants further allege that the aforementioned acts of removing copyright notice, title, identifying information and terms of use were done intentionally and knowingly to facilitate infringement of the copyrighted material. Count 6: Competition deemed to be unfair by Common Law owing to Misappropriation of the Copyrighted Material against all defendants The plaintiffs allege that the defendants have copied the content over which the plaintiff had a copyright and without the consent of the plaintiff the defendants trained their LLM That, the defendants removed tags which would indicate that the plaintiff had a copyright over the content and the aforementioned act of the plaintiff has caused monetary loss to The New York Times Company. Relief Sought by The New York Times Company In light of the allegations made against Microsoft Corporation, OpenAI Inc. et. al. the plaintiff seeks the following: Compensation in the form of statutory damages, compensatory damages, disgorgement and other relief permitted by the law of equity. An injunction enjoining the defendants from infringing the copyrighted content of The New York Times Company. A court order demanding the destruction of GPT Models which were built on the content over which The New York Times Company had a copyright. Attorney’s fees. Additional Allegations and Context Fair Use and Training AI Models: OpenAI has argued that the utilisation of copyrighted material for AI training can be viewed as transformative use, potentially qualifying for protection under the fair use doctrine. This argument is central to the ongoing debate about the extent to which AI can utilise existing copyrighted works to create new, generative content. OpenAI's Response to the Lawsuit: OpenAI has publicly responded to the lawsuit, asserting that the case lacks merit and suggesting that The New York Times may have manipulated prompts to generate the replicated content. OpenAI has also mentioned its efforts to reduce content replication from its models and highlighted The New York Times' refusal to share examples of this reproduction before filing the lawsuit. Impact on AI Research and Development The lawsuit raises significant questions about the future of AI research and development, particularly regarding the balance between copyright protection and the necessity for AI models to access a wide range of data to learn and tackle new challenges. OpenAI has stressed the importance of accessing "the enormous aggregate of human knowledge" for effective AI functioning. The case is being closely monitored as it could establish precedents for how AI companies utilise copyrighted content. Potential Implications of the Lawsuit Precedent-Setting Case This lawsuit is one of the first instances where a major media organisation is taking legal action against AI companies for copyright infringement. The outcome of this case could establish a legal precedent for how copyrighted content is employed to train AI models. Innovation vs. Copyright Protection The case underscores the tension between fostering innovation in AI and safeguarding the rights of copyright holders. The court's decision could have far-reaching implications for both AI advancement and the protection of intellectual property. Conclusion and Next Steps The case is currently pending in the United States District Court for the Southern District of New York. The court's rulings on various counts of copyright infringement, vicarious and contributory copyright infringement, and unfair competition will be pivotal in determining the lawsuit's outcome. The lawsuit might prompt other copyright holders to evaluate how their content is utilised by AI companies and could result in additional legal actions or calls for legislative amendments to address the use of copyrighted material in AI training datasets. Both parties may continue to explore potential solutions, which could include licensing agreements, the development of AI models that do not rely on copyrighted content, or the establishment of industry standards for the ethical utilization of data in AI.
- Artificial Intelligence Governance using Complex Adaptivity: Feedback Report, First Edition, 2024
This is a feedback report developed to offer inputs to a coveted paper published by the Economic Advisory Council to the Prime Minister (EAC-PM) of India, entitled “A Complex Adaptive System Framework to Regulate Artificial Intelligence” authored by Sanjeev Sanyal, Pranav Sharma, and Chirag Dudani. You can access the complete feedback report here. This report provides a detailed examination of the EAC-PM paper "A Complex Adaptive System Framework to Regulate Artificial Intelligence." It delves into the core principles proposed by the authors, including instituting guardrails and partitions, ensuring human control, promoting transparency and explainability, establishing distinct accountability, and creating a specialized, agile regulatory body.Through a series of infographics and concise explanations, the report breaks down the intricate concepts of complex adaptivity and its application to AI governance. It offers a fresh perspective on viewing AI systems as complex adaptive systems, highlighting the challenges of traditional regulatory approaches and the need for adaptive, responsive frameworks. Key Highlights: In-depth analysis of the EAC-PM paper's recommendations for AI regulation. Practical feedback and policy suggestions for each proposed regulatory principle. Insights into the unique characteristics of AI systems as complex adaptive systems. Exploration of financial markets as a real-world example of complex adaptive systems. Recommendations for a balanced approach fostering innovation and responsible AI development. Whether you are a policymaker, researcher, industry professional, or simply interested in the future of AI governance, this report provides a valuable resource for understanding the complexities involved and the potential solutions offered by a complex adaptive systems approach. Download the "Artificial Intelligence Governance using Complex Adaptivity: Feedback Report" today and gain a comprehensive understanding of this critical topic. Engage with the thought-provoking insights and contribute to the ongoing dialogue on responsible AI development.Stay informed, stay ahead in the era of AI governance. About the EAC-PM Paper The paper proposes a novel framework to regulate Artificial Intelligence (AI) by viewing it through the lens of a Complex Adaptive System (CAS). Traditional regulatory approaches based on ex-ante impact analysis are inadequate for governing the complex, non-linear and unpredictable nature of AI systems.The paper conducts a comparative analysis of existing AI regulatory approaches across the United States, United Kingdom, European Union, China, and the United Nations. It highlights the gaps and limitations in these frameworks when dealing with AI's CAS characteristics.To effectively regulate AI, the paper recommends a CAS-inspired framework based on five guiding principles: Instituting Guardrails and Partitions: Implement clear boundary conditions to restrict undesirable AI behaviours. Create "partitions" or barriers between distinct AI systems to prevent cascading systemic failures, akin to firebreaks in forests. Ensuring Human Control via Overrides and Authorizations: Mandate manual override mechanisms for human intervention when AI systems behave erratically. Implement multi-factor authentication protocols requiring consensus from multiple credentialed humans before executing high-risk AI actions. Transparency and Explainability: Promote open licensing of core AI algorithms for external audits. Mandate standardized "AI factsheets" detailing system development, training data, and known limitations. Conduct periodic mandatory audits for transparency and explainability. Distinct Accountability: Establish predefined liability protocols and standardized incident reporting to ensure accountability for AI-related malfunctions or unintended outcomes. Implement traceability mechanisms throughout the AI technology stack. Specialized, Agile Regulatory Body: Create a dedicated regulatory authority with a broad mandate, expertise, and agility to respond swiftly to emerging AI challenges. Maintain a national registry of AI algorithms for compliance and a repository of unforeseen events. The paper draws insights from the regulation of financial markets, which exhibit CAS characteristics with emergent behaviours arising from diverse interacting agents. It highlights regulatory mechanisms like dedicated oversight bodies, transparency requirements, control chokepoints, and personal accountability measures that can inform AI governance.
- [Draft] Artificial Intelligence Act for India, Version 2
The Artificial Intelligence (Development & Regulation) Bill, 2023 (AIACT.In) Version 2, released on March 14, 2024, builds upon the framework established in Version 1 while introducing several new provisions and amendments. This draft legislation proposed by our Founder, Mr Abhivardhan, aims to promote responsible AI development and deployment in India through a comprehensive regulatory framework. Please note that draft AIACT.IN (Version 2) is an Open Proposal developed by Mr Abhivardhan and Indic Pacific Legal Research, and is not a draft legislation proposed by any Ministry of the Government of India. You can access and download the Version 2 of the AIACT.IN by clicking below. Key Features of Artificial Intelligence Act for India [AIACT.In] Version 2 Categorization of AI Systems: Version 2 introduces a detailed categorization of AI systems based on conceptual, technical, commercial, and risk-centric methods of classification. This stratification helps in identifying and regulating AI technologies according to their inherent purpose, technical features, and potential risks. Prohibition of Unintended Risk AI Systems: The development, deployment, and use of unintended risk AI systems, as classified under Section 3, is prohibited in Version 2. This provision aims to mitigate the potential harm caused by AI systems that may emerge from complex interactions and pose unforeseen risks. Sector-Specific Standards for High-Risk AI: Version 2 mandates the development of sector-specific standards for high-risk AI systems in strategic sectors. These standards will address issues such as safety, security, reliability, transparency, accountability, and ethical considerations. Certification and Ethics Code: The IDRC (IndiaAI Development & Regulation Council) is tasked with establishing a voluntary certification scheme for AI systems based on their industry use cases and risk levels. Additionally, an Ethics Code for narrow and medium-risk AI systems is introduced to promote responsible AI development and utilization. Knowledge Management and Decision-Making: Version 2 emphasizes the importance of knowledge management and decision-making processes for high-risk AI systems. The IDRC is required to develop comprehensive model standards in these areas, and entities engaged in the development or deployment of high-risk AI systems must comply with these standards. Intellectual Property Protections: Version 2 recognizes the need for a combination of existing intellectual property rights and new IP concepts tailored to address the spatial aspects of AI systems. The IDRC is tasked with establishing consultative mechanisms for the identification, protection, and enforcement of intellectual property rights related to AI. Comparison with AIACT.In Version 1 Expanded Scope: Version 2 expands upon the regulatory framework established in Version 1, introducing new provisions and amendments to address the evolving landscape of AI development and deployment. Detailed Categorization: While Version 1 provided a basic categorization of AI systems, Version 2 introduces a more comprehensive and nuanced approach to classification based on conceptual, technical, commercial, and risk-centric methods. Sector-Specific Standards: Version 2 places a greater emphasis on the development of sector-specific standards for high-risk AI systems in strategic sectors, compared to the more general approach taken in Version 1. Knowledge Management and Decision-Making: The importance of knowledge management and decision-making processes for high-risk AI systems is highlighted in Version 2, with the IDRC tasked with developing comprehensive model standards in these areas. This aspect was not as prominently featured in Version 1. Intellectual Property Protections: Version 2 recognizes the need for a combination of existing intellectual property rights and new IP concepts tailored to AI systems, whereas Version 1 did not delve into the specifics of intellectual property protections for AI. Detailed Description of the Features of AIACT.IN Version 2 Significance of Key Section 2 Definitions Section 2 of AIACT.IN provides essential definitions that signify the legislative intent of the Act. Some of the key definitions are: Artificial Intelligence: The Act defines AI as an information system that employs computational, statistical, or machine-learning techniques to generate outputs based on given inputs. This broad definition encompasses various subcategories of technical, commercial, and sectoral nature, as set forth in Section 3. AI-Generated Content: This refers to content, physical or digital, that has been created or significantly modified by an artificial intelligence technology. This includes text, images, audio, and video created through various techniques, subject to the test case or use case of the AI application. Algorithmic Bias: The Act defines algorithmic bias as inherent technical limitations within an AI product, service, or system that lead to systematic and repeatable errors in processing, analysis, or output generation, resulting in outcomes that deviate from objective, fair, or intended results. This includes technical limitations that emerge from the design, development, and operational stages of AI. Combinations of Intellectual Property Protections: This refers to the integrated application of various intellectual property rights, such as copyrights, patents, trademarks, trade secrets, and design rights, to safeguard the unique features and components of AI systems. Content Provenance: The Act defines content provenance as the identification, tracking, and watermarking of AI-generated content using a set of techniques to establish its origin, authenticity, and history. This includes the source data, models, and algorithms used to generate the content, as well as the individuals or entities involved in its creation, modification, and distribution. Data: The Act defines data as a representation of information, facts, concepts, opinions, or instructions in a manner suitable for communication, interpretation, or processing by human beings or by automated or augmented means. Data Fiduciary: A data fiduciary is any person who alone or in conjunction with other persons determines the purpose and means of processing personal data. Data Portability: Data portability refers to the ability of a data principal to request and receive their personal data processed by a data fiduciary in a structured, commonly used, and machine-readable format, and to transmit that data to another data fiduciary. Data Principal: The data principal is the individual to whom the personal data relates. In the case of a child or a person with a disability, this includes the parents, lawful guardian, or lawful guardian acting on their behalf. Data Protection Officer: A data protection officer is an individual appointed by the Significant Data Fiduciary under the Digital Personal Data Protection Act, 2023. Digital Office: A digital office is an office that adopts an online mechanism wherein the proceedings, from receipt of intimation or complaint or reference or directions or appeal, as the case may be, to the disposal thereof, are conducted in online or digital mode. Digital Personal Data: Digital personal data refers to personal data in digital form. Digital Public Infrastructure (DPI): DPI refers to the underlying digital platforms, networks, and services that enable the delivery of essential digital services to the public, including digital identity systems, digital payment systems, data exchange platforms, digital registries and databases, and open application programming interfaces (APIs) and standards. Knowledge Asset: A knowledge asset includes intellectual property rights, documented knowledge, tacit knowledge and expertise, organizational processes, customer-related knowledge, knowledge derived from data analysis, and collaborative knowledge. Knowledge Management: Knowledge management refers to the systematic processes and methods employed by organizations to capture, organize, share, and utilize knowledge assets related to the development, deployment, and regulation of AI systems. IDRC: IDRC stands for IndiaAI Development & Regulation Council, a statutory and regulatory body established to oversee the development and regulation of AI systems across government bodies, ministries, and departments. Inherent Purpose: The inherent purpose refers to the underlying technical objective for which an AI technology is designed, developed, and deployed, encompassing the specific tasks, functions, and capabilities that the AI technology is intended to perform or achieve. Insurance Policy: Insurance policy refers to measures and requirements concerning insurance for research and development, production, and implementation of AI technologies. Interoperability Considerations: Interoperability considerations are the technical, legal, and operational factors that enable AI systems to work together seamlessly, exchange information, and operate across different platforms and environments. Open Source Software: Open source software is computer software that is distributed with its source code made available and licensed with the right to study, change, and distribute the software to anyone and for any purpose. National Registry of Artificial Intelligence Use Cases: The National Registry of Artificial Intelligence Use Cases is a national-level digitized registry of use cases of AI technologies based on their technical & commercial features and inherent purpose, maintained by the Central Government for the purposes of standardization and certification of use cases of AI technologies. These definitions provide a clear understanding of the scope and intent of AIACT.IN, ensuring that the Act effectively addresses the complexities and challenges associated with the development and regulation of AI systems in India. Here is a list of some FAQs (frequently asked questions, that are addressed in detail. Here is how you can participate in the AIACT.IN discourse: Read and understand the document: The first step to participating in the discourse is to read and understand the AIACT.IN Version 2 document. This will give you a clear idea of the proposed regulations and standards for AI development and regulation in India. To submit your suggestions to us, write to us at vligta@indicpacific.com. Identify key areas of interest: Once you have read the document, identify the key areas that are of interest to you or your organization. This could include sections on intellectual property protections, shared sector-neutral standards, content provenance, employment and insurance, or alternative dispute resolution. Provide constructive feedback: Share your feedback on the proposed regulations and standards, highlighting any areas of concern or suggestions for improvement. Be sure to provide constructive feedback that is backed by evidence and data, where possible. Engage in discussions: Participate in discussions with other stakeholders in the AI ecosystem, including industry experts, policymakers, and researchers. This will help you gain a broader perspective on the proposed regulations and standards, and identify areas of consensus and disagreement. Stay informed: Keep up to date with the latest developments in the AI ecosystem, including new regulations, standards, and best practices. This will help you stay informed and engaged in the discourse, and ensure that your feedback is relevant and timely. Collaborate with others: Consider collaborating with other stakeholders in the AI ecosystem to develop joint submissions or position papers on the proposed regulations and standards. This will help amplify your voice and increase your impact in the discourse. Participate in consultations: Look out for opportunities to participate in consultations on the proposed regulations and standards. This will give you the opportunity to share your feedback directly with policymakers and regulators, and help shape the final regulations and standards. You can even participate in the committee sessions & meetings held by the Indian Society of Artificial Intelligence and Law. To participate, you may contact the Secretariat at executive@isail.co.in.
- USPTO Inventorship Guidance on AI Patentability for Indian Stakeholders
The United States Patent and Trademark Office (USPTO) has recently issued guidance that seeks to clarify the murky waters of AI contributions in the realm of patents, a move that holds significant implications not just for American innovators but also for Indian stakeholders who are deeply entrenched in the global innovation ecosystem.As AI continues to challenge the traditional notions of creativity and inventorship, the USPTO's directions may serve as a beacon for navigating these uncharted territories. Let's see. For Indian researchers, startups, and multinational corporations, understanding and adapting to these guidelines is not just a matter of legal compliance but a strategic imperative that could define their competitive edge in the international market. In this insight, we will delve into the nuances of the USPTO's guidance on AI patentability, exploring its potential impact on the Indian landscape of innovation. We will examine how these directions might shape the future of AI development in India and what it means for Indian entities to align with global standards while fostering an environment that encourages human ingenuity and protects intellectual property rights. Through this lens, we aim to offer a comprehensive analysis that resonates with the ethos of Indian constitutionalism and the broader aspirations of India's technological advancement. The Inventorship Guidance for AI-Assisted Inventions This guidance, which went into effect on February 13, 2024, aims to strike a balance between promoting human ingenuity and investment in AI-assisted inventions while not stifling future innovation. We must remember that the Guidance did refer the DABUS cases in which Stephen Thaler's petitions on declaring an AI to be an inventor were denied. The USPTO's guidance emphasises that AI-assisted inventions are not categorically unpatentable, but rather, the human contribution to an innovation must be significant enough to qualify for a patent when AI also contributed. The guidance provides instructions to examiners and stakeholders on determining the correct inventor(s) to be named in a patent or patent application for inventions created by humans with the assistance of one or more AI systems.The issue of inventorship in patent law for AI-created inventions remains of particular importance to companies that develop and use AI technology. While AI has unquestionably created novel and nonobvious results, the question of whether AI can be an "inventor" under U.S. patent law remains unanswered. The USPTO's guidance reiterates that only a natural person can be an inventor, so AI cannot be listed as an inventor. However, the guidance does not provide a bright-line test for determining whether a person's contribution to an AI-assisted invention is significant enough to qualify as an inventor. The ability to obtain a patent on an invention is a critical means for businesses to protect their intellectual property and maintain a competitive edge. Also, the requirement that an "inventor" be a natural person might not be at odds with the reality of AI-generated inventions. As the conversation around AI inventorship unfolds, companies should be aware of alternative ways to protect their AI-generated inventions, such as using trade secrets. The USPTO's guidance on AI patentability is a significant step towards providing clarity to the public and USPTO employees on the patentability of AI-assisted inventions. The USPTO has provided examples in their guidance to illustrate the application of the guidance. Let's understand the examples provided by them: AI-generated drug discovery: In this example, a researcher uses an AI system to analyze a large dataset of chemical compounds and identify potential drug candidates. The AI system suggests a novel compound that the researcher synthesizes and tests, confirming its efficacy. The guidance indicates that the researcher would be considered the inventor, as they made a significant contribution to the conception of the invention by selecting the dataset, designing the AI system, and interpreting the results. AI-generated materials design: In this example, a materials scientist uses an AI system to design a new material with specific properties. The AI system suggests a novel material composition, which the scientist then fabricates and tests, confirming its properties. The guidance indicates that the scientist would be considered the inventor, as they made a significant contribution to the conception of the invention by defining the problem, selecting the AI system, and interpreting the results. AI-generated image recognition: In this example, a software engineer uses an AI system to develop an image recognition algorithm. The AI system suggests a novel neural network architecture, which the engineer then implements and tests, confirming its performance. The guidance indicates that the engineer would be considered the inventor, as they made a significant contribution to the conception of the invention by defining the problem, selecting the AI system, and implementing the suggested architecture. The guidance is open to comments until May 13, 2024, and may change, but in the meantime, inventors seeking patent protection for their AI-assisted inventions should consider carefully documenting the human contribution on a claim-by-claim basis, including the technology used, the nature and details of the AI system's design, build, and training, and the steps taken to refine the AI system's outputs. Implications for Indian Research Institutions The USPTO's guidance on AI patentability could have significant implications for Indian research institutions, which are at the forefront of AI innovation. The recent memorandum of understanding between the USPTO and the Indian Patent Office at Kolkata to cooperate on IP examination and protection could facilitate collaboration and intellectual property sharing between Indian researchers and global partners. This agreement could pave the way for joint research projects, knowledge exchange, and capacity building in the field of AI.Moreover, the growing partnership between the US and India in scientific research could further strengthen collaboration in AI. The US National Science Foundation and Indian science agencies have agreed to launch 35 jointly funded projects in space, defense, and new technologies, including AI. This initiative could encourage higher-education institutions in both countries to collaborate on AI research and development, leading to new discoveries and innovations.However, regulatory bureaucracy and visa processing delays could pose challenges to scientific collaboration between India and the US. To overcome these obstacles, Indian research institutions could assign a designated individual to manage joint programs and projects with US partners, as suggested by Heidi Arola, assistant vice-president for global partnerships and programmes at Purdue University. Choosing the right institutional partner with compatible goals is also crucial for successful collaboration. Impact on Indian Startups and Entrepreneurs The USPTO's guidance on AI patentability presents both challenges and opportunities for Indian startups and entrepreneurs seeking international patents. The guidance emphasises the need for a significant human contribution to the conception or reduction to practice of the invention, which could make it more difficult for AI-focused startups to secure patents. However, the guidance also provides clarity on the patentability of AI-assisted inventions, which could help startups navigate the patent application process more effectively.Clarity in AI patentability could also affect investment and growth in the Indian startup ecosystem. Investors may be more likely to fund startups with a clear path to patent protection, leading to increased innovation and economic growth. Moreover, the USPTO's initiatives to increase participation in invention, entrepreneurship, and creativity, such as the Patent Pro Bono Program and the Law School Clinic Certification Program, could provide valuable resources and support to Indian startups and entrepreneurs. Relevance for Indian Industry and Multinational Corporations Indian industries and multinational corporations operating in India must navigate patent filings in light of the USPTO's guidance on AI patentability. The guidance emphasizes that AI cannot be an inventor, coinventor, or joint inventor, and that only natural persons can be named as inventors in a patent application. This could have significant implications for companies developing AI-based inventions, as they must ensure that human contributors are properly identified and credited.Moreover, the potential need for harmonization of patent laws to facilitate cross-border innovation and protect intellectual property could affect Indian industries and multinational corporations. The USPTO's Intellectual Property Attaché Program, which has offices and IP experts located full-time in New Delhi, could provide valuable assistance to U.S. inventors, businesses, and rights holders in resolving IP issues in the region. However, Indian companies may also need to engage with local IP offices and legal counsel to develop an overall IPR protection strategy and secure and register patents, trademarks, and copyrights in key foreign markets. Understanding Readiness on AI Patentability for India As the world continues to focus on AI's potential, Indian regulators may not require to respond to the USPTO's guidance and the broader global discourse on AI inventorship by clarifying the patent eligibility framework for AI-related inventions in India, for now. The reason is obvious. In a recent response in the Rajya Sabha, a Minister of State (MoS) of the Ministry of Commerce and Industry reiterated that AI-generated works, including patents and copyrights, can be protected under the current IPR regime. This statement, while seemingly obvious, holds significance for India's position in the global AI landscape. Under international copyright law, only individuals, groups of individuals, and companies can own the intellectual properties associated with AI. The MoS's statement aligns with this principle, indicating that India is open to nurturing AI innovations within the existing legal framework. This position could be interpreted as an invitation for investment and economic opportunities in the AI sector, potentially positioning India as a safe and reasonable hub for AI development. However, it is crucial for governments to carefully observe and address attempts by big companies to promote anti-competitive AI regulations. Creating a separate category of rights for AI-generated works could lead to challenges in compensating for and justifying contributions to the intellectual property, as well as the associated economic ramifications. Andrew Ng, a prominent figure in the AI community, has expressed concerns about big companies pushing for anti-competitive AI regulations. He notes that while the conversation around AI has become more sensible, with fears of AI extinction risk fading, some large corporations are still advocating for regulations that could stifle innovation and competition in the AI sector. One of the specific points made by Ng is the ongoing fight to protect open-source AI. Open-source AI refers to the practice of making AI software, algorithms, and models freely available for anyone to use, modify, and distribute. This approach fosters collaboration, accelerates innovation, and democratises access to AI technology. However, some big companies may seek to impose restrictions on open-source AI through regulations, potentially limiting its growth and impact. An example of the importance of open-source AI can be seen in the development of popular AI frameworks like TensorFlow and PyTorch, which have become essential tools for AI researchers and developers worldwide. These open-source projects have enabled rapid progress in AI by allowing researchers to build upon each other's work and share new ideas more easily. Furthermore, recent research from the University of Copenhagen suggests that achieving Artificial General Intelligence (AGI) may not be as imminent as some believe. The study argues that current AI advancements are not directly leading to the development of AGI, which is the hypothetical ability of an AI system to understand, learn, and apply knowledge across a wide range of tasks at a level comparable to a human being. This research underscores the importance of maintaining a competitive and innovative AI landscape, as the path to AGI remains uncertain and may require ongoing collaboration and breakthroughs. There is another perspective for the Indian ecosystem to consider: R&D and innovation appetite. The insight shared by Amit Sethi, a Professor at the Indian Institute of Technology, Bombay, highlights a significant issue in India's AI landscape. Despite the ongoing AI funding summer in India, the best AI talent in the country is still primarily focused on fine-tuning existing AI models rather than developing cutting-edge AI technologies. This situation poses several challenges for India's AI aspirations. India's AI funding summer, which has seen significant investments in AI startups like Krutrim AI and RagaAI, is yet to produce credible AI use cases. The demand for generative AI services is rising, but the Indian AI ecosystem needs to mature to deliver on this potential. Nandan Nilekani, the visionary behind India's Aadhaar, emphasizes the importance of developing micro-level or smaller AI use cases instead of attempting to create large models like OpenAI. However, the challenge lies in identifying and standardizing AI model weights for smaller, limited-application use cases that can work effectively over the long term. India's tech policy on AI, including the IndiaAI initiative, cannot succeed without prioritizing local capabilities. The Indian tech ecosystem must focus on nurturing homegrown companies to create wealth and intellectual property. An American semiconductor company CEO also emphasized that India needs to capitalize on the AI revolution through homegrown companies rather than relying on multinational corporations. Some major Indian companies are developing AI use cases that are becoming knock-offs or heavily reliant on models built by OpenAI, Anthropic, and others. This dependence on external AI models should be avoided to foster genuine innovation in the Indian AI landscape. Suggestions for Indian Stakeholders Indian stakeholders, including research institutions, startups, and industries, should prepare for possible changes in patent law and international intellectual property norms by: Staying informed about the latest developments in AI patentability, both in India and globally. Ensuring that AI-related inventions meet the fundamental legal requirements of novelty, inventive step, and industrial application. Focusing on integrating AI features into practical applications to demonstrate a technical contribution or technical effect. Providing clear and definitive empirical determinations of technical contributions and technical effects in patent applications. Engaging with policymakers and patent offices to advocate for a balanced approach to AI patentability that protects the rights of inventors while fostering innovation. Conclusion Understanding the USPTO's AI patentability guidance is crucial for Indian stakeholders, as it could significantly impact the growth of AI-related inventions in the country. By proactively engaging with global patentability standards and adapting to changes in patent law, Indian stakeholders can support innovation in India's research, startup, and industry sectors. As the world continues to grapple with the challenges and opportunities presented by AI inventorship, India has the potential to emerge as a leader in AI-related patent filings and contribute to the global discourse on AI patentability.
- AI-Generated Texts and the Legal Landscape: A Technical Perspective
Artificial Intelligence (AI) has significantly disrupted the competitive marketplace, particularly in the realm of text generation. AI systems like ChatGPT and Bard have been used to generate a wide array of literary and artistic content, including translations, news articles, poetry, and scripts[8]. However, this has led to complex issues surrounding intellectual property rights and copyright laws[8]. Copyright Laws and AI-Generated Content AI-generated content is produced by an inert entity using an algorithm, and therefore, it does not traditionally fall under copyright protection[8]. However, the U.S. Copyright Office has recently shown openness to granting ownership to AI-generated work on a "case-by-case" basis[5]. The key factor in determining copyright is the extent to which a human had creative control over the work's expression[5]. The AI software code itself is subject to copyright laws, and this includes the copyrights on the programming code, the machine learning model, and other related aspects[8]. However, the classification of AI-generated material, such as writings, text, programming code, pictures, or images, and their eligibility for copyright protection is contentious[8]. Legal Challenges and AI The New York Times (NYT) has recently sued OpenAI and Microsoft for copyright infringement, contending that millions of its articles were used to train automated chatbots without authorization[2]. OpenAI, however, has argued that using copyrighted works to train its technologies is fair use under the law[6]. This case highlights the ongoing legal battle over the unauthorized use of published work to train AI systems[2]. Paraphrasing and AI Paraphrasing tools, powered by AI, have become increasingly popular. These tools can rewrite, enhance, and repurpose content while maintaining the original meaning[7]. However, the use of such tools has raised concerns about the potential for copyright infringement and plagiarism. To address this, it is suggested that heuristic and semantic protocols be developed for accepting and rejecting AI-generated texts[3]. AI-based paraphrasing tools, such as Quillbot and SpinBot, offer the ability to rephrase text while preserving the original meaning. These tools can be beneficial for students and professionals alike, aiding in the writing process by providing alternative expressions and avoiding plagiarism. However, the accuracy and ethical use of these tools are concerns. For example, a student might use an AI paraphrasing tool to rewrite an academic paper, but without a deep understanding of the content, the result could be a superficial or misleading representation of the original work. This raises questions about the integrity of the paraphrased content and the student's learning process. It's crucial to develop guidelines for the ethical use of paraphrasing tools, ensuring that users engage with the original material and properly attribute sources to maintain academic and professional standards. Citation and Referencing in the AI Era The advent of AI-generated texts has necessitated a change in the concept of citation and referencing. Currently, the American Psychological Association (APA) recommends that text generated from AI be formatted as "Personal Communication," receiving an in-text citation but not an entry on the References list[4]. However, as AI-generated content becomes more prevalent, the nature of primary and secondary sources might change, and the traditional system of citation may need to be permanently altered. For instance, the Chicago Manual of Style advises treating AI-generated text as personal communication, requiring citations to include the AI's name, the prompt description, and the date accessed. However, this approach may not be sufficient as AI becomes more prevalent in content creation. Hypothetically, consider a scenario where a researcher uses an AI tool to draft a section of a literature review. The current citation standards would struggle to accurately reflect the AI's contribution, potentially leading to issues of intellectual honesty and academic integrity. As AI-generated content becomes more sophisticated, the distinction between human and AI authorship blurs, prompting a need for new citation frameworks that can accommodate these changes. Content Protection and AI The rise of AI has also raised concerns about the protection of gated knowledge and content. Publishing entities like NYT and Elsevier may need to adapt to the changing landscape[1]. The protection of original content in the age of AI is a growing concern, especially for publishers and content creators. The New York Times' lawsuit against OpenAI over the use of its articles to train AI models without permission exemplifies the legal challenges in this domain. To safeguard content, publishers might consider implementing open-source standards for data scraping and human-in-the-loop grammatical protocols. Imagine a small online magazine that discovers its articles are being repurposed by an AI without credit or compensation. To combat this, the magazine could employ open-source tools to track the use of its content and ensure that any AI-generated derivatives are properly licensed and attributed, thus maintaining control over its intellectual property. The rapid advancement of AI technologies has brought about significant changes in the legal and technical landscape. As AI continues to evolve, it is crucial to address the legal implications of AI-generated texts and develop protocols to regulate their use. This will ensure the protection of intellectual property rights while fostering innovation in AI technologies. References [1] https://builtin.com/artificial-intelligence/ai-copyright [2] https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html [3] https://www.semrush.com/goodcontent/paraphrasing-tool/ [4] https://dal.ca.libguides.com/CitationStyleGuide/citing-ai [5] https://mashable.com/article/us-copyright-law-ai-generated-content [6] https://www.nytimes.com/2024/01/08/technology/openai-new-york-times-lawsuit.html [7] https://www.hypotenuse.ai/paraphrasing-tool [8] https://www.legal500.com/developments/thought-leadership/legal-issues-with-ai-generated-content-copyright-and-chatgpt/ [9] https://www.cnbc.com/2024/01/08/openai-responds-to-new-york-times-lawsuit.html [10] https://www.copy.ai/tools/paraphrase-tool [11] https://www.techtarget.com/searchcontentmanagement/answer/Is-AI-generated-content-copyrighted [12] https://www.theverge.com/2024/1/8/24030283/openai-nyt-lawsuit-fair-use-ai-copyright [13] https://www.scribbr.com/paraphrasing-tool/ [14] https://www.reddit.com/r/selfpublishing/comments/znlqla/what_is_the_legality_of_ai_generated_text_for/ [15] https://theconversation.com/how-a-new-york-times-copyright-lawsuit-against-openai-could-potentially-transform-how-ai-and-copyright-work-221059 [16] https://ahrefs.com/writing-tools/paraphrasing-tool [17] https://www.jdsupra.com/legalnews/relying-on-ai-generated-text-and-images-9943106/ [18] https://apnews.com/article/nyt-new-york-times-openai-microsoft-6ea53a8ad3efa06ee4643b697df0ba57 [19] https://quillbot.com [20] https://crsreports.congress.gov/product/pdf/LSB/LSB10922 [21] https://www.reuters.com/legal/transactional/ny-times-sues-openai-microsoft-infringing-copyrighted-work-2023-12-27/ [22] https://www.paraphraser.io [23] https://www.pcmag.com/news/ai-generated-content-and-the-law-are-you-going-to-get-sued [24] https://pressgazette.co.uk/media_law/new-york-times-open-ai-microsoft-lawsuit/ [25] https://textflip.ai
- The French, Italian and German Compromise on Foundation Models of GenAI
The author is pursuing law studies at National Law University, Odisha and is a former Research Intern at the Indian Society of Artificial Intelligence and Law. Almost every economy around the world is trying to curate a model that would put guardrails on the AI technology that is rapidly developing all around the world and is being increasingly used by people. Like other economies, the European Union (EU) is trying to lead the world in developing AI technology and in coming up with an efficient and effective way to regulate it. In mid-2023, the EU passed one of the first major laws to regulate AI which was a model that would aid policymakers. The European Parliament, for example, had passed a draft law, the EU AI Act, which would impose restrictions on the technology’s riskiest uses. Unlike the United States, which has taken up the challenge to create such a model quite recently, the EU has been trying to do so for more than two years. They took it up with greater urgency after the release of ChatGPT in 2022. On 18 November 2023, Germany, France, and Italy reached an important pact on AI regulation and released a joint non-paper that countered some basic approaches undertaken by the EU AI Act. They suggested alternate approaches that they claim would be more feasible and efficient. The joint non-paper underlines that the AI Act must aim to regulate the application of AI and not the technology itself because innate risks lie in the former and not in the latter. The joint non-paper highlights some key areas in which they beg to differ from the point of view of the AI Act passed by the Parliament. The highlights are: Fostering innovation while balancing responsible AI adoption within the EU The joint paper pushes for mandatory self-regulation for foundation models and advocate for stringent control over AI's foundational models, aiming to enhance accountability and transparency in the AI development process. While the EU AI Act targets only major AI producers, the joint paper advocates for a universal adherence to avoid compromising trust in the security of smaller EU companies. Immediate sanctions for defaulters of codes of conduct are excluded but a future sanction system is proposed. The focus is on regulating the application of AI and not the AI technology itself. Therefore, the development process of AI models should not be subject to regulation. What are Foundation Models of AI? Foundation models, also called general purpose AI, are AI systems which can be used to conduct a wide range of tasks that pertain to various fields such as understanding language, generating text and images, and conversing in natural language. This can be done so without majorly modifying and fine-tuning them. They can be used through several innovative methods. They are deep learning neural networks that change the approach adopted by machine learning. Data scientists use foundation models as starting points of developing AI instead of starting from scratch. This makes the process fast and cost-effective. The European Union AI Act The EU AI Act is a comprehensive framework of law that governs the sale and use of AI in EU. It sets consistent standards for AI systems across EU. It tries to address the risks of AI through obligations and standards that intend to safeguard the safety and fundamental rights of citizens in the EU and globally. It works as a part of a wider legal and policy framework and regulates different aspects of the digital economy which includes General Data Protection Regulation, the Digital Services Act, and the Digital Markets Act. It moves away from a “one law fixes all” approach to this emerging AI regime. Risk-based Approach of the AI Act versus the joint pact of FR, IT and DE One of the key aspects of the AI Act is to regulate foundation models that support a wide range of AI applications. The most prominent AI companies like OpenAI, Google DeepMind, and Meta develop such foundation models. The AI Act aims to regulate these models by running safety tests and apprise the governments of their results in order to ensure accountability and transparency and to mitigate risks. The recent U.K. AI Safety Summit focused on risks associated with the most advanced foundation models. So basically, it is the technology that is regulated in order to manage risks. The joint non-paper aims to change this narrative of regulating the technology to regulating the application of the technology. Developers of foundation models would have to publish the kinds of testing done to ensure their model is safe. No sanctions would be applied initially to companies who did not publish this information as per the code of conduct, but the non-paper suggests a future sanction system could be set up in future. The three countries oppose the “two-tier” approach to foundation model regulation, originally proposed by the EU because it would impose stricter regulations on the most capable models expected to have the largest impact. It will hit on the legs of innovation and hamper the growth of AI technologies. French company Aleph Alpha and German company Mistral AI, which are the most prominent AI companies of Europe, are opposed to this approach of risk management. The discourse on how regulation should happen and adopting an optimal strategy would require a close look at the pros of cons of each approach i.e. regulation of the technology (EU’s two tier approach) and regulation of the applications of the technology (Franco-German-Italian view). Regulating the technology itself Pros: Directly regulating the technology establishes uniform and consistent standards which all applications can adopt. This gives clarity in compliance. Technological regulation can prevent creation and use of harmful and malicious AI applications. Cons: Strict regulations on the technology will hamper and stifle innovation by limiting the exploration of potentially beneficial applications. Technological advancements happen much faster than prescriptive regulations. The very purpose of regulations will be defeated if it fails to regulate the advanced versions of the technology. Regulating the application of technology Pros: When regulation is application-specific, it allows for a flexible approach where rules of risk mitigation can be tailored according to different applications and their uses instead of a one size fits all approach which is impractical. Regulations based on application can help to focus on responsible use of the technology and on measures of accountability in case potential risks manifest themselves. It still permits smooth flow of innovation. Cons: A risk of ignoring certain aspects of AI technology remains if the regulation is solely focused on applications, which may leave for misuse or unintended effects. Desirably, a balanced approach that combines elements of both technology-focused and application-focused regulation can be most effective. This can be done by curating rules and standards for the technology itself and also framing regulations specific to the potential risks associated with their application. But a case must be made which opines that regulation of the application of technology is a better way to go because, in a world where use of technology in the day to day life has become the norm for many, stifling innovation, which is a direct result of regulating technology, can be a bad idea. Technological advancements are required because everyone has the psychological tendency to get their work done easily and quickly, especially when society is evolving to increase employment and involvement of people in skilled work. Focus must be on ensuring the large masses of people benefit from the boons of the AI technology while ensuring that incentives for bad actors are minimised through regulation of the use of AI tools. This is to be done by increasing accountability on its use, by giving proper guidance on how to use it efficiently and ethically and how to prevent potential harms that can arise from uninformed or irresponsible use. The Model Cards requirement under mandatory self-regulation The non-paper proposes regulating specific applications rather than foundation models, aligning more with the risk-based approach. It requires defining model cards as a means to achieve such an approach. Defining model cards is a mandatory element of self-regulation. This means foundation model developers would have to define model cards, including technical documentation that presents information about trained models in an accessible way, following best practices within the developers’ community. Defining model cards promotes the principle of ‘transparency of AI’. Model cards require inclusion of limits on intended uses, potential limitations, biases, and security assessments. But it only advises users to make decisions of purchasing or not. But when it comes to recognising the transparency, accountability, and responsible AI criteria, then many users might find it highly complex to comprehend due to the technical nature of AI applications. They will not be able to adequately interpret the information on model cards. Model cards are more accessible to developers and researchers with a high level of education in AI. So there arises an imbalance of power between developers and users regarding the understanding of AI. Standardization of information remains an anomaly if model cards are used. Providing a high volume of information in model cards may confuse users. Maintaining a balance between transparency and simplicity is crucial. Users may not be aware of the existence of model cards or may not take the time to review them, especially in cases where AI systems are very complex. The model card requirement may lack feasibility because there is no scope of external monitoring over its elements. It is inflexible to the pace in which technology develops and so its information can get outdated, resulting in stifling innovation by binding new technologies with outdated compliances and information.
- OpenAI's Qualia-Type 'AGI' and Cybersecurity Dilemmas
The author of this insight is pursuing law at National Law University, Odisha and a former research intern at the Indian Society of Artificial Intelligence and Law. OpenAI CEO Sam Altman was fired from its Board of Directors for a short spell in November 2023. Along with him, another member of the Board, Grog Brockman, was also fired. Both the spokespersons of OpenAI and these two people refused to provide any reasons for this when they were reached out to. However, it came to light that several researchers and staff of OpenAI had written a letter to the Board, before the firing, warning of a powerful artificial intelligence discovery that they said could threaten humanity. OpenAI was initially created as a non-profit organisation whose mission was “to ensure that artificial general intelligence benefits all of humanity.”[1] Later, in 2019, it opened up a for-profit branch. This was a cause of concern because it was anticipated that this for-profit wing will dilute the original mission of OpenAI to develop AI for the benefit of humanity and will rather act for profit, which can often lead to non-adherence to ethical growth of the technology. Sam Altman and Grog Bockman were in favour of strengthening this wing while the other 4 Board members were against giving too much share power to it and instead, wanted to stick to developing AI for human benefit rather than to achieve business goals. It was cited by OpenAI that Sam Altman was not consistent with his communication with the rest of the Board regarding the development of a long-anticipated breakthrough - Q* AI model which is a Artificial General Intelligence (AGI) model that can surpass all existing AI developments and can achieve tasks and goals way beyond what we can imagine AI to do currently. OpenAI defines AGI as autonomous systems that surpass humans in most economically valuable tasks. It was presumed that CEO Altman had knowledge of advanced developments regarding AGI within OpenAI. It was reported in the media that he had concealed facts from the Board of Directors, leading them to firing him. With several debates going around about this in the AI community, including within OpenAI employees who protested against his firing, Altman’s position was restored and structural changes within OpenAI were suggested that includes the involvement of people like Satya Nadella. But the concern is that, with its advanced abilities, Q* AGI could be problematic for being opaque. Any presumed form of AGI would naturally work on reinforcement learning at least based on the current scientific knowledge we have. In machine learning (ML), a drawback is the vast amount of data that models require for training. The more the complexity in the model, the more data it requires. Still, the data may not be reliable. It may have false or missing values or may be collected from untrustworthy sources. Reinforcement Learning overcomes the problem of data acquisition by almost completely removing the need for data. Reinforcement learning is a branch of ML that trains a model to come to an optimum solution for a problem by taking decisions by itself. This feature is what gives AGI its strong capabilities. It has vast computing capabilities which can help it to predict most future events and phenomena including the fluctuations in stock and investment markets, advanced weather conditions, election outcomes and much more. It can use its mathematical algorithms and other complex technical elements to foresee how the human mind will think and traverse, thus gaining outcome knowledge and taking decisions that can alter and influence many things. One of the biggest apprehensions behind the development of Q* technology was that it could pose a cybersecurity risk to national governments and their classified data. Can QUALIA crack Advanced Encryption Standards (AES) which uses bitcoin-like blockchain and encryption technology to protect classified information and documents? How can major cyber security breaches affect us? How to safeguard against such cyber security breaches? These are some questions one must consider. Some Considerations We depend a lot on encryption for securing our data. It might be perceivable that the encryption safeguards that we rely on keep our data secure. That is not true entirely. As discussed before, tech like Q* has the ability to break AES as well. It may have accomplished a feat that was once considered impossible, to break modern encryption. The recent LLaMA leak on 4chan suggests that Q* can solve AES-192 and AES-256 encryption using a ciphertext attack. With AES compromised, the entire digital economy can fall apart. Government secrets, healthcare data, banking data, etc., can be exposed. The NSA has previously shown interest in breaking encryption through their Project Tundra which is similar to the alleged capabilities of Q*. This raises questions about the ethical implications of such AI advancements by state and non-state actors. Recommendations Standards and Certifications There needs to be implementation of mandatory legislation that requires nations and specific organizations to have minimum cyber security standards in place. There should be a self-regulatory set of standards to help organizations develop their cyber security measures. States must establish a Computer Incident Response Team, a national Network and Information Systems (NIS) authority and a national NIS strategy. Companies must adopt state of the art security approaches that are appropriate to manage the risks posed to their systems. Another element of standards and certification can be a regulation on a set of standards for electronic identification and trust services for electronic transactions. Regulation of Encryption standards Sensitive data can be protected by ensuring efficient encryption measures. Data must be classified based on its sensitive nature and significance. Investing on equally encrypting all types of data is unnecessary. More sensitive data requires a greater and stronger level of encryption with added layers of security. When and how encryption should be applied is a major consideration here. A multi-factor authentication is recommended to add an extra layer of security, even if an attacker gains access to encrypted data keys. It is recommended that the best industry practices are adopted while doing so. End-to-End encryption is a best practice to protect data throughout its entire lifecycle, from creation to storage to transmission. Strong and widely accepted encryption algorithms that are fully updated must be used and there should be periodic checks of upgradation requirements. Conducting regular audits and assessments is necessary and there must be a supervisory body that ensures these regular checks. Regulating reinforcement learning Regulation of reinforcement learning by AI must be done which involves establishing guidelines and frameworks in order ensure responsible and ethical use. Transparency in the development and deployment of RL algorithms is crucial. RL developers should create a manual which provides information about the algorithms' goals, training data, and decision-making processes. This should be done, especially where RL is used in critical applications that can affect society. Liability mechanisms must be in place for holding developers and organizations accountable for the actions of RL algorithms. Frameworks must be developed for comprehensively defining the rights and liabilities in case losses occur and harm is caused by RL-based AI systems. When personal data of individuals are involved, privacy concerns emerge. Measures must be implemented to ensure compliance with data protection regulations and safeguard user privacy. Since billions of people are currently using AI tools in various aspects of their lives, it is necessary for them to have a basic knowledge about RL technology. Definitely policymakers, developers, and the general public must understand the benefits and potential risks associated with RL so that they can make informed choices about their use and create effective policies. It is a good idea to collaborate with international organizations and regulatory bodies to establish consistent global standards for RL. Cyber security insurance Cyber insurance is important with the development of AI because there will be a new set of risks that tradition insurance policies may not cover. Some risks can be data breaches, property damage, business interruption, or even physical harm to humans. It is quite unpredictable what kind of risks AGI models may pose. Also, malicious actors will misuses these models who may try to steal, corrupt, or manipulate them for their own purposes and insurance must definitely cover resulting losses. AI systems may also fail unintentionally due to faulty assumptions, design flaws, or unexpected situations that may produce unsafe or undesirable outcomes. This is another area where cyber insurance can help cover the costs and liabilities associated with these potential failures and provide guidance and support for preventing them. Legal regulation Existing legal instruments may not be enough to cover and address the risks that will accompany security breaches by AGI. Integrating AI security requirements into existing data protection laws is necessary and every national parliament must develop and committee consisting of AI and legal experts who will draft stringent laws to prevent any cyber security breach by AGI models once they come to use. References [1] https://openai.com/about


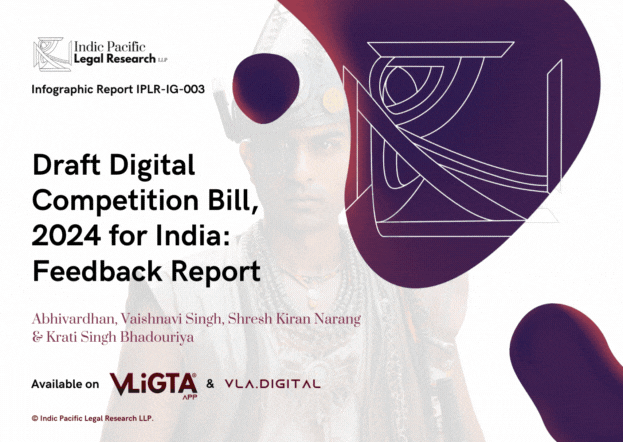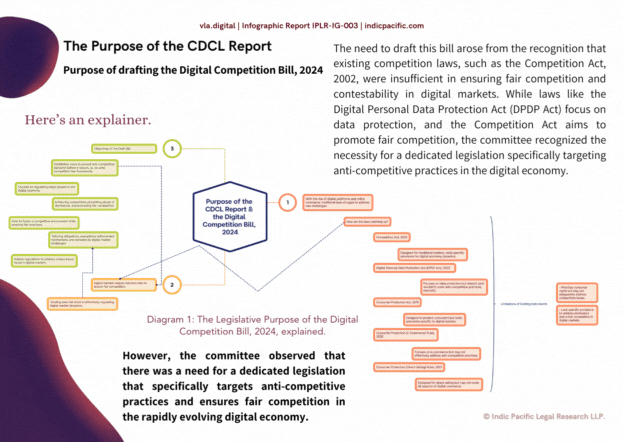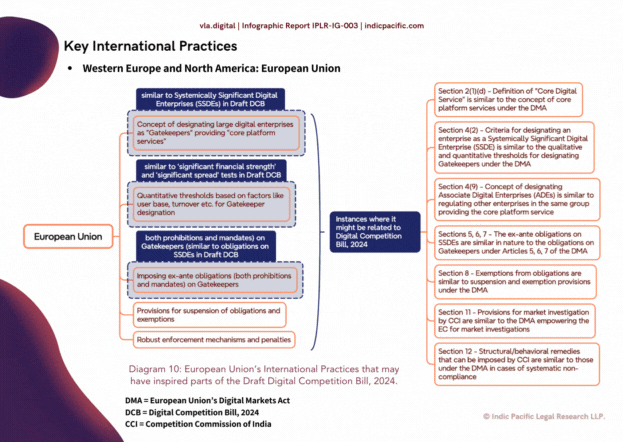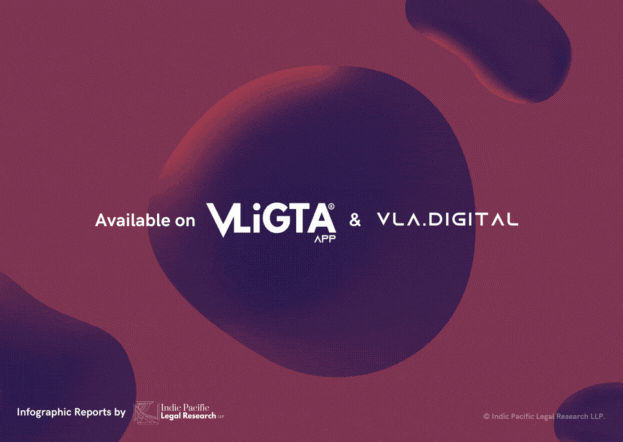



![[Draft] Artificial Intelligence Act for India, Version 2](https://static.wixstatic.com/media/f0525d_0e961118df0041bd8e94c05226d6eb88~mv2.jpg/v1/fill/w_93,h_66,al_c,q_80,blur_2,enc_auto/f0525d_0e961118df0041bd8e94c05226d6eb88~mv2.jpg)



