


Examining Legal and Economic Risks around AGI Hype & Doomerism post-GPT-5
- Abhivardhan

- Aug 15, 2025
- 11 min read
Updated: Aug 15, 2025

The release of GPT-5 by OpenAI has raised questions in the global AI economy, from multiple frontiers - technology viability, model explainability, economic logic, future of work and even on narratives of doom.
For more than 6 months and so, Indic Pacific Legal Research has been the sole legal consultancy and research firm, which had uncovered the economic and contract law perspective of AI Doomerism and AGI hype around large language models and their impact, endorsing the perspectives of healthy critics.
The reason we covered such perspectives was precisely because we believe that AI can be a driver of growth, if the frontiers of AI research and commercialisation are not hyped in bad faith.
In that context, this insight focuses on the technical, product management and economic failures of GPT-5, based on our previous research around OpenAI's relationship with Microsoft, and how AI hype was perpetuated by researchers and executives at this company. Again - the purpose of this insight is not to make ad hominem remarks on OpenAI, since we have examined economic law and technology policy considerations around other companies as well (e.g., Perplexity, Anthropic, etc.).

In addition, this insight examines the real-time economic law risks that would exist in a post-GPT-5 global economy, considering that Indic Pacific is the only research firm that has published extensive works on AI hype and digital competition law since 2021. We are also the only legal research firm in India which has developed a teaching module on AI hype in our AI and commercial law training programmes (do check them out at indicpacific.com/train).
But first, let's understand an AI Bubble and how it creates Economic Law Issues.
The AI Bubble and how it creates Economic Law Issues
Several investor reports, including the infamous 300+ page report on AI Investment trends by a technology investment firm, BOND protect some interesting numbers around AI use, and the proliferation of data centres. While some of the projections made could or could not be true, our concern as a technology law consulting firm was around the economic law impact of the “AI Bubble”.
So let’s ask: is there a real AI “Bubble”? If yes, then what?
There have been some significant AI advancements, for sure. However:
most of those advancements are not delivering a consistent business and knowledge worker model for AI startups to self-sustain themselves in the long-run;
the legal implications are muddy because despite the absence or presence of AI regulations across the globe, the market sentiment around AI is mixed due to the unreliability of the larger large language models-led ecosystem due to:
behavioural issues in the LLM and large vision models segment (hallucination, lack of model explainability, consent manipulation causing consumer and vendor-level trust issues)
AI compute becoming the most significant resource burden for most AI startups to scale, grow or even make revenues
lack of trustworthy market practices despite the omnipotence of AI systems impacting multiple sectors either indirectly, or through solving market & public governance challenges.
In fact, our research suggests that models like GPT-5, Grok and others have plateaued and apart from larger models like Gemini, Claude and Qwen’s latest version as of August 15, 2025, the “bigger” large language models may not yield as per reasonable market expectations. Here is a list of some of our research coverage on AI Hype / AGI Hype and Economic Law before you do a deep dive into this insight:
January 2025 to July 2025
Artificial Intelligence, Market Power and India in a Multipolar World, August 15, 2025 [Technical Report in partnership with Schematise LDA and ExtensityAI, available on IndoPacific.App]
Why India Needs to Shape AI and Future of Work Narratives Delicately, July 30, 2025 [Originally published in abhivardhan.substack.com, re-published in VLA.Digital]
The Illusion of Thinking: Apple's Groundbreaking Research Exposes Critical Limitations in AI Reasoning Models, June 9, 2025 [VLA.Digital]
Indo-Pacific Research Ethics Framework on Artificial Intelligence Use, IPac AI, April 25, 2025 [Handbook presented to Manipal Academy for Higher Education, available on IndoPacific.App]
Averting Framework Fatigue in AI Governance, IPLR-IG-013, February 3, 2025 [Technical Report, available on IndoPacific.App]
July 2024 to December 2024
Beyond AGI Promises: Decoding Microsoft-OpenAI's Competition Policy Paradox, December 9, 2024 [VLA.Digital]
Legal-Economic Issues in Indian AI Compute and Infrastructure, IPLR-IG-011, October 11, 2024 [Technical Report, available on IndoPacific.App]
Impact-Based Legal Problems around Generative AI in Publishing, IPLR-IG-010, September 13, 2024 [Technical Report, available on IndoPacific.App]
Microsoft's Calculated 'Competition' with OpenAI, August 4, 2024 [VLA.Digital]
TESCREAL and AI-related Risks, July 15, 2024 [VLA.Digital]
November 2022 to September 2023
Auditing AI Companies for Corporate Internal Investigations in India, VLiGTA-TR-005, September 28, 2023 [Technical Report, available on IndoPacific.App]
Deciphering Regulative Methods for Generative AI, VLiGTA-TR-002, May 22, 2023 [Technical Report, available on IndoPacific.App]
AI Regulation and the Future of Work & Innovation, April 11, 2023 [VLA.Digital]
ChatGPT & the Problem with Derivatives as Solutions (Check the "Competition Law Concerns on Derivative Products" section specifically), February 16, 2023 [VLA.Digital]
Deciphering Artificial Intelligence Hype and its Legal-Economic Risks, VLiGTA-TR-001, November 25, 2022 [Technical Report, available on IndoPacific.App]
While all of this might make no direct sense as to why market hype still matters, we have to understand that while a market can involve in promoting AI products and services - many of which might lack any reliability or customer / vendor value, the legal implications do not end since many AI risks naturally emerge.
Please note that an AI risk does not emerge because an AI regulation has defined it. Yes, regulations are important in categorising what constitutes a “risk” in fields like data protection, cybersecurity, trade secrets and others. However, AI risks happen by design because AI (which is an umbrella term) involves systems which can automate or augment.
Now, even if they don’t offer DIRECT VALUE at times, as we know it, their spread in the market creates sufficient legal and ethical challenges for multiple stakeholders:
Governments, because they have to eventually regulate;
Investors, because they have to invest in entities which deliver value in some shape or form;
Incubators, because while AI has a lot of scope to cover, it needs a business model that makes a company / startup survive in these times;
Researchers in the AI space, because they publish technology papers to keep their credibility alive;
Vendors, because they engage in general or hybrid solutions in the larger technology value and supply chain.
We kind of anticipated this very well, since Indic Pacific Legal Research had published around 15 Publications on AI Hype and Economic Law (check the list above), covering very simple questions:
What are the features of market hype in the context of AI technologies?
Does this form of market hype constitute anti-competitive practices?
How does this affect the global AI talent ecosystem?
How does it affect any AI company to have a sustainable business model?
How do we ensure that a potential AI company sustains well but also undergoes a form of technology law compliance (in data protection, AI and IP), which not only delivers their business goals but also strengthens the resilience of their organisation. amidst regulatory uncertainty?
In this 16th insight, we cover the Economic Law problems associated with GPT-5.
Distortion of Global-Scale AI Layers - Data, Algorithms, Application, Cloud and Compute

To keep things specific, the post-ChatGPT 3.5 situation had started fuelling more infrastructure push and investment in the language models, vision models and cloud fronts. Even in a May 2025 report (around 300+ pages long) by BOND, a Tech Investment Consulting, these slides from the document show how where they envisioning the whole AI investment landscape (check Figures 3 and 4).

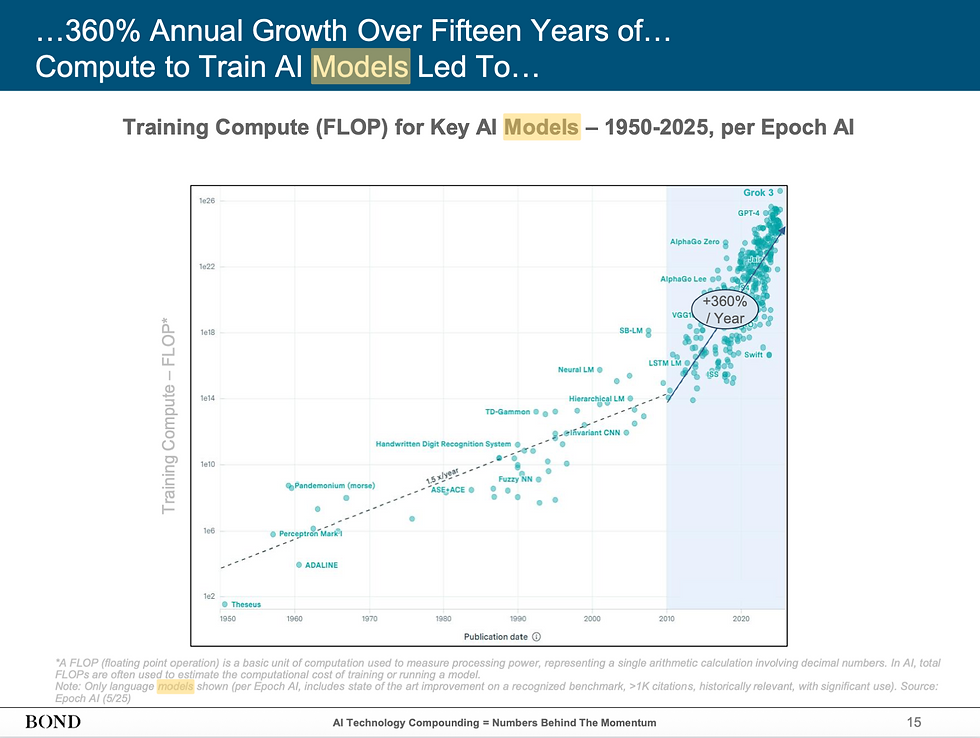
Now, these figures have their own meaning. However, the launch of GPT-5 has ignited a new situation, months after the launch of DeepSeek R1 in January 2025, which is important to understand, as explained in Figure 5.
The core distribution shift problem identified by AI researchers decades ago remains unsolved in GPT-5, as demonstrated by a recent Arizona State University study that found chain-of-thought reasoning to be "a brittle mirage that vanishes when it is pushed beyond training distributions". This research validates long-standing criticisms from experts like Gary Marcus.
The failure to generalise beyond training data explains why GPT-5 performs only marginally better than competing models like Grok 4, and actually performs worse on certain benchmarks such as ARC-AGI-2.
The problem of AI-generated misinformation persists even in cutting-edge language models. According to OpenAI's internal metrics, their flagship GPT-5 model produces false information in nearly one out of ten responses (9.6%) when connected to online resources. Remove internet connectivity, and this error rate skyrockets to nearly half of all outputs (47%). The issue extends across the industry: research examining various AI systems for scientific literature synthesis revealed that GPT-4 generated inaccurate content in more than a quarter of cases (28%), while Google's Bard demonstrated an alarming propensity for fabrication, producing false information in over nine out of ten responses (91.4%).

This means the following:
Unless dataset used for AI training and feedback looping purposes post-training lacks contextual relevance, and no data quality focus remains, it would not lead to more effective and helpful AI research in future. Hence, a turnaround is plausibly expected.
LLMs have technological behaviour issues (see this insight) among which hallucinations are high-level business and research credibility risks. Scaling would not help which has been proven by a paper published by the Machine Learning division of Apple and other institutions.
While the infrastructure push to have more data centres would not be hampered, the access costs and their ecosystem relevance from an economic angle might be questioned by market players. This is where governments might have to step up under their AI industry missions and initiatives and support AI talent within their jurisdiction to fuel more AI research efforts as soon as possible (for example in India).
Compute may still remain "king" since:
the plunge faced by companies like NVIDIA in the US stock markets during the launch of DeepSeek R1 was due to dependency on market players in the cloud, data, AI models and application space, and
a lot of hype made around GPT 4 and subsequent models by OpenAI, several AI investors, a lot of influencers and some management & legal "thought leaders" directly impacted the market when DeepSeek became relatively more efficient. Of course a ripple effect was imminent.

Since innovations in the compute space would not be impacted since they are a separate industry altogether beyond the GenAI global economy, maybe their adoption can slow down due to the costs skyrocketing for a long time around the trend of "model tokenisation".

Quite interestingly, the Reddit post above (which Deedy Das on X pointed out) - became the #1 post in the sub-Reddit of OpenAI. The perspectives are interesting. Another interesting fact is that 3,300+ people demanded to bring GPT 4o back in a change.org petition. That is also worth noting.
The post-Bletchey Appoach of AI Safety is Now Obsolete
This will offend some desperate policy think tanks in New Delhi, Bengaluru, London and New York, but AI "Alignment" in line with OpenAI's own alignment research has failed abruptly due to the technological behaviour issues associated with LLMs.
Alignment Research doesn't work, because it doesn't inform stakeholders at any level of data and AI governance effectively as to what form of compliance or strategy works.
For example, an AI compliance specialist would not be able to figure out how exactly a typical "AI agent" fails or works successfully because they are not reliable to be defended.
A Product Manager would not be able to help because for them - there is no post-prototype aspect of the AI system, which makes it possible to be productised.
However, an AI developer will be easily able to figure out systemic failures, even if they cannot understand what granular level of model explainability is even achievable. To quote Raphaelle d'Ornano:
Agentic AI leads to what I call orchestration economics and looking at historical growth will not help determine future winners.” - Raphaelle d'Ornano
There are serious data protection and leakage issues (which include cybersecurity risks) that cannot be bypassed.
The future of work implications are too unclear here - because while agentic AI doesn't "replace" any technical professionals and even coders, the labour ethics dilemmas can easily come.
For example - it is completely understandable that companies wish to go lean and cut their workforce, since they also made hirings in an inflated sense before, or their list of work expectations wasn't cut out well, causing and creating inflated employment scope and menial work requirements, coupled with menial pay requirements.

Again - the AI anxiety in the corporate world fuelled this, and not AI agents or any LLM by virtue of its technical and business use cases. However, the impact of hype is such that it makes company boards and managerial teams think they are not doing enough and could be left far behind.
However, "orchestration economics" doesn't ensure better labour standards in a flexible sense, and creates a lot of muddy waters, which companies like Meta and XAI did through their hiring spree of the AI talent, creating anxiety in the job market. Everyone "will know everything" as pointed out by Parmita Mishra, who is leading a AI and genetics startup, Precigenetics (see Fig. 8). How can India's so-called tech policy think tank geniuses in Delhi and Bengaluru justify such a market-bending and talent-distracting approach towards our AI talent, is beyond our understanding.

This further proves that the field of technology law due to the economics and reliability issues associated with large language models (or prediction machines) will become as complicated as taxation law sooner than before. It's just going to happen because of uncertainties created in the global markets by several key players.
Plus, there will be an economic angle to this, which is important to be addressed, which is also addressed pretty neatly by Chip Joyce in this article (check the excerpt from his article in Fig. 9). Pure scaling isn't the correct approach, and it's better that the sophisticated possibilities around symbolic AI and explainability of ML systems is taken into regard while making way for better AI governance approaches in the global market.
Our Recommendations
Build effective business models around AI systems which involves truer multidisciplinary and technical expertise, not only in terms of who can build ML / AI systems which are more explanatory or workable, or but also in terms of who can create feedback loops to improve the human-AI intermingling of these ML / AI systems as a third-party stakeholder.
Data protection, cybersecurity and intellectual property laws are not ending, so do invest in contractual and cross-border market cooperation measures by building legal strategies that make sense for all sorts of teams in an AI startup and even larger enterprises. Respect and engage with domain experts in technology law, instead of relying on corporate lawyers who have no idea (for instance) how even a data processing clause or a privacy policy is developed. At Indic Pacific, we aim to help people with domain-specific needs, and if you need support, please contact us.
Unique datasets are key to enable better neurosymbolic AI solutions or LLM-based workflows which work within limited compute. Hence, if you feel that your idea needs time, validate it first through a solid technical and explanatory basis, and then think of a business scaling paradigm which doesn't force you to overinvest in AI compute due to market hype.
Engage in AI standardisation efforts by developing community-led feedback loops. This makes your market participation a bit more foolproof after you have achieved some technical breakthrough or throughput. Organisations like the Indian Society of Artificial Intelligence and Law, Data Science and AI Association of Australia and others engage in such practices, so you can contact them.
LLM Research is not ending soon, but it will plateau since market hype cycles are eventually broken. Hence, be prepared.



Comments